Using a performance monitoring system that you built yourself? You are not alone! Many organizations monitor their applications and IT infrastructure with a bolted-together and often incompatible assortment of tools. With larger organizations this can number to a dozen or more different tools. Seriously. Build vs. Buy, Do-It-Yourself (DIY), homegrown, in-house, Not Invented Here (NIH) — there are almost as many terms to describe this approach as there are products to do the monitoring.
There’s a good chance you’re using tools like Statsd, Graphite, Nagios and others to stay on top of things. But that’s a LOT of work. And why spend all the time doing all that work yourself? Life, as we all know, is too short. Is glueing together N tools or building yet another custom monitoring tool really a good use of (y)our (life)time? This also leads to the next obvious question:
Why Not Use One Monitoring Solution to Do It All?
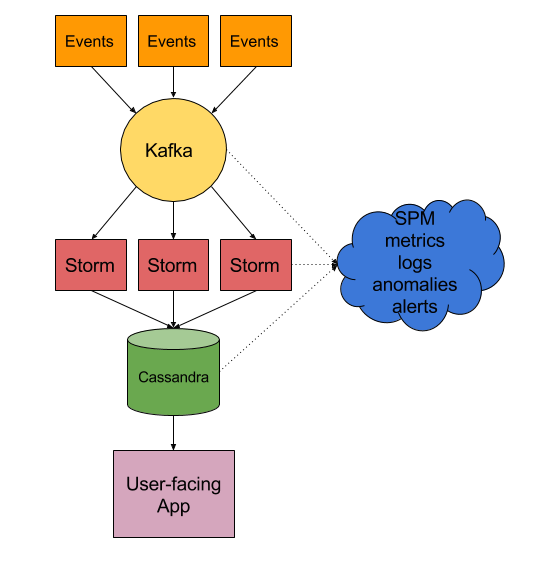
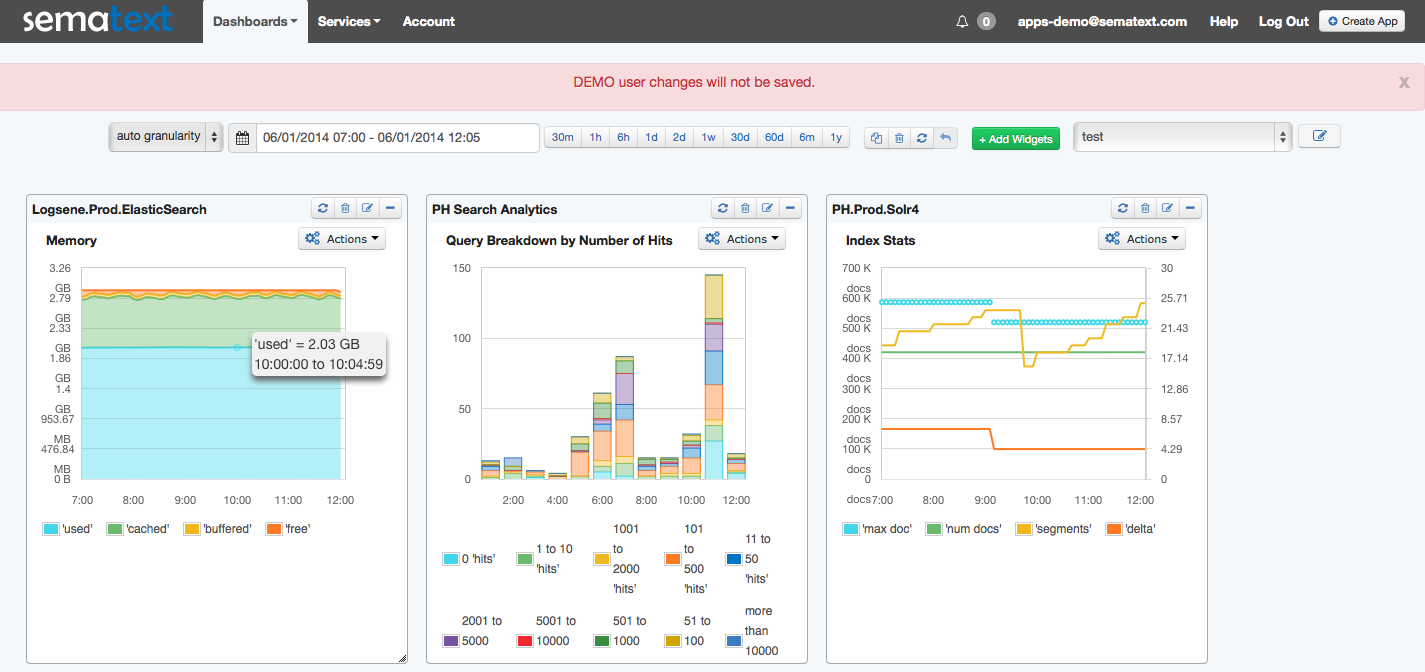
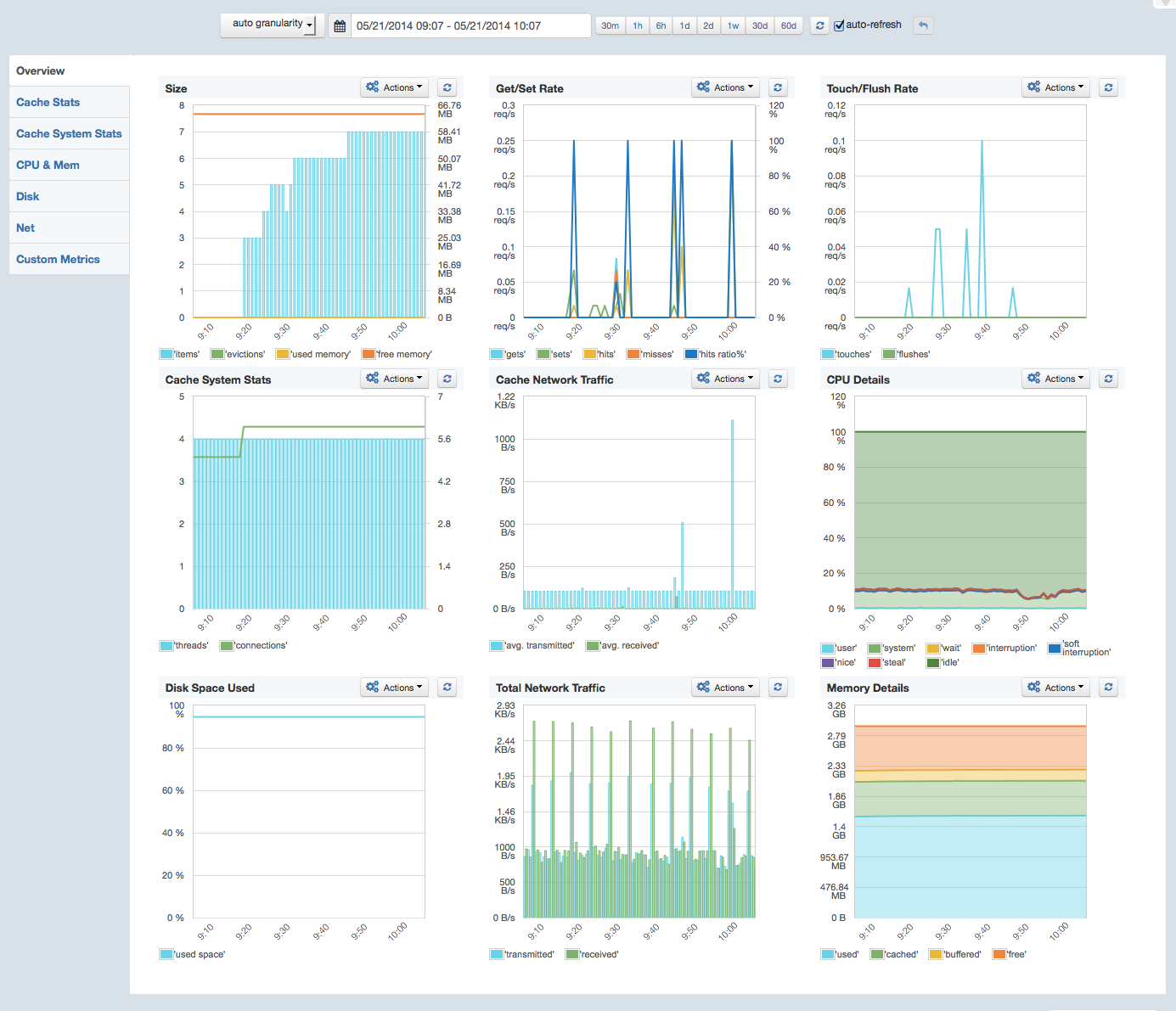
SPM Performance Monitoring, Alerting and Anomaly Detection is a comprehensive solution that does the work of many individual monitoring tools in one powerful package. Applications, servers, other key IT devices — even logs! — are all covered. A partial list of monitored apps includes Elasticsearch, Solr, Hadoop, HBase, Spark, Cassandra, Kafka, Storm, Redis, NGINX Plus and NGINX. You can even see what I’m talking about right now by checking out our SPM live demo.
In fact, as one SPM user recently told us:
“I don’t want to be a data ape and consume your data to build other reports. I think that is one of the attractions with SPM — I can push the data to Graphite or another monitoring tool, but you already have the reports done. So my time to insight is much faster.”
There Are Some Huge Differences Between Building and Buying
If your Building approach is draining engineer time that could be better spent elsewhere, then you should consider some of the key differences between building your own monitoring “system” and using SPM, including:
- Log & Event Correlation: SPM can aggregate, graph and correlate logs with performance metrics and alerts (via integration with Logsene Log Management and Analytics). If you are managing your logs then you are using a separate solution that does not integrate with your “Build” monitoring system. Being able to see logs along with performance metrics is essential for effective troubleshooting.
- On Premises or in Cloud: SPM offers an On Premises version in addition to SaaS. Most app-specific monitoring tools are SaaS-only, but some organizations like their metrics and logs close to home base.
- Native App Monitoring vs. 3rd Party Plugins: SPM monitors all apps natively. If you are monitoring a number of individual apps via a range of 3rd party plugins then you have to deal with multiple installation and data collection mechanisms, various levels of maturity, and widely varying qualities of implementation and of reporting.
- Anomaly Detection: SPM has support not only for heartbeat alerts and threshold-based alerts, but also for automatic machine learning based anomaly detection. A Build system most likely does not have comprehensive anomaly detection capabilities.
And Then There is the Cost of Using All Those Different Monitoring Tools…
Cost comparisons between Building your own monitoring system and Buying a solution like SPM are not linear. While some monitoring tools are open-source and free (though the time to configure them can be costly in its own right), commercial tools run a wide gamut of costs, infrastructure limits, data limits, time limits, pricing schemes, etc. Just keeping track of the costs is often a job in itself. In general, the more tools you have, the more value SPM delivers.
Here’s one scenario that will give you an idea of potential Build costs:
Build Your Own Monitoring System — Cost Scenario
- Hourly rate: $100 (ballpark figure; could be much higher)
- Installation: 2 hours (very optimistic)
- Configuration: 8 hours (very optimistic)
- Maintenance: 2 hours/month (optimistic)
- Upgrading: 2 days (i.e., ~20 hours)/year (IF all goes well!)
- # of servers to run this configuration: 3 (monitoring 10 total servers*)
- Cost per server (hardware): $1,000 each (i.e., $3,000 total)
___________________________________________________________
- Total Cost in Year 1: $6,200
- Total Cost in Year 2: $3,200 (not including any additional server purchases)
- Total Cost in Year 3: $3,200 (at least, though most likely higher)
And we didn’t even count the time cost to actually learn how to use all these tools!
Moreover, we used very optimistic numbers, assumed nothing will go wrong, assumed no issues like backwards incompatibilities, problems around dependencies, etc. etc. – all issues that are actually very common and can consume days and make the above costs much higher. We do a ton of DevOps work at Sematext and, like everyone in this field, know how common this is.
* this number can vary widely, but for example purposes, if you want a complete monitoring solution that can do everything SPM can do — monitoring, alerting, anomaly detection, graph emailing, embedding, etc. — then the total servers that can be monitored with 3 monitoring servers will be lower than it would with a bare bones, incomplete monitoring tool.
SPM — Cost Scenario
- # of servers: 10 servers (for example purposes)
- Standard plan (our lowest cost plan beyond Free): $25/server/month
- Time to Register and Install N agents: 1 hour (or $100 at hourly rate)
________________________________________________________________
- Total Cost in Year 1: $3,100
- Total Cost in Year 2: $3,000
- Total Cost in Year 3: $3,000
And these costs don’t even include any Volume Discounts that we would offer!
You can find clear, simple pricing plans for SPM right here.
Conclusion
While it’s great that there are many tools available for monitoring — some of them free — and communities built around those tools, in the DevOps world it still comes back to time. Time to learn these tools. Time to stay up-to-date on them. Time to deploy. Time to configure. Time to maintain. Time to assemble a bunch of disparate tools so you can monitor more than just one app. You get the picture. And time, as we all know, carries a cost. With DevOps this is typically a significant cost. So before undertaking a long and neverending “Build” journey, it makes sense to look at all the costs — in money and time — of buying a complete monitoring solution like SPM vs. building your own system. The closer you look, the more value a tool like SPM offers you and your organization.
Try SPM for Free for 30 Days
Tired of building, and building, and building… Try SPM Performance Monitoring for Free for 30 days by registering here. There’s no commitment and no credit card required.