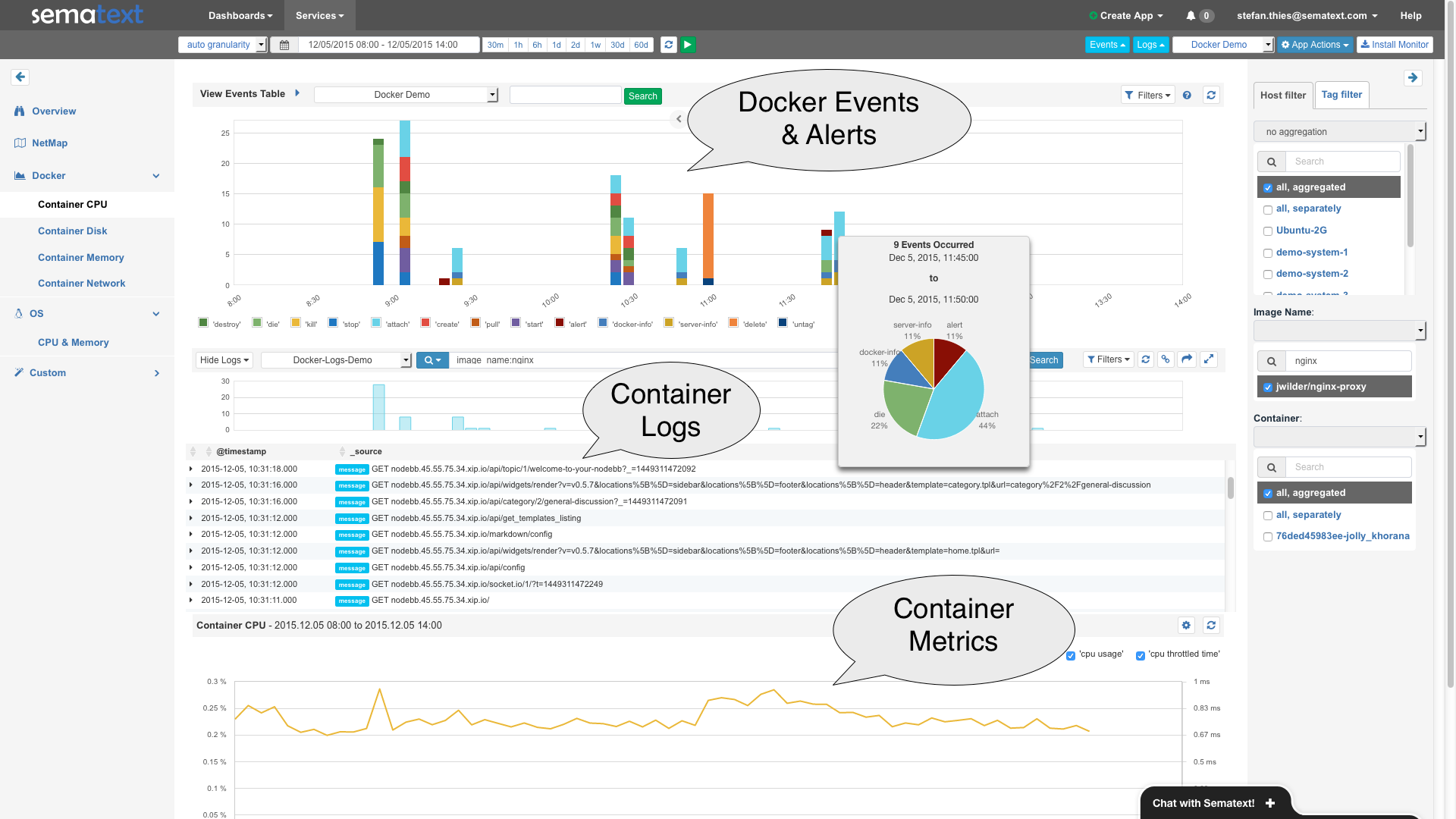
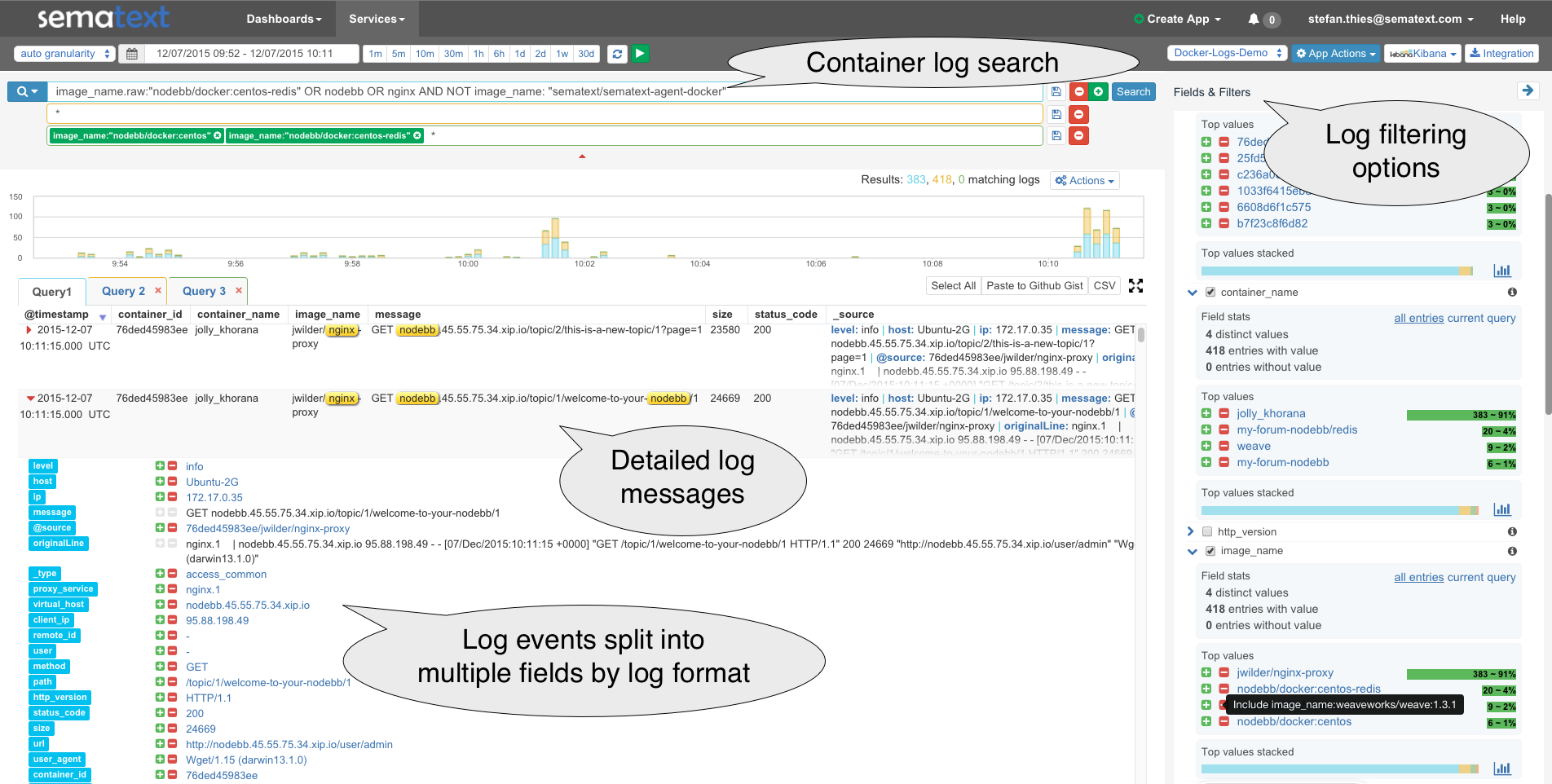
Last week, we upgraded Logsene to Elasticsearch v2.2.0 including the required upgrade to Kibana 4.3.1. This means you can benefit from Elasticsearch 2.2.0, Kibana 4.3.1 and the updated Logsene UI using Elasticsearch 2.x features. In addition, we migrated all existing data from Elasticsearch 1.7 to Elasticsearch 2.2, that’s why you might have noticed a slight delay in processing of logs recently.
There is a long list of “breaking changes” in Elasticsearch 2.x. However, you won’t notice most of these changes – this is why it pays to use a managed service like Logsene 🙂 That said, a few of them, such as breaking changes in Elasticsearch Mapping (the “database schema”) will have an impact oh how logs should be structured before you ship them to Logsene:
- Elasticsearch 2.x does not accept documents containing Elasticsearch metadata field names. Field names starting with underscore (“_”) are reserved for Elasticsearch metadata and should not be used in indexed documents (e.g. _type, _id, _ttl, …). This means existing log shipper configurations, which generated such fields should be changed.
- Field names may not contain dots, e.g. “memory.free” is not a valid field name anymore. This must be changed to a JSON structure {“memory”: { “free”: 110234}} or the field name needs a different separator e.g. “memory_free” instead of “memory.free”.
The good news: Both cases are transparently handled for you in the current Logsene Receiver. While Logsene handles this for you automatically, we strongly suggest you make the required changes. Logsene detects malformed field names and renames them to valid field names in Elasticsearch. The automatic field renaming follows a simple method:
1) Remove leading underscores
2) Replace dots with underscores
Please check if your log data is affected by this change. Please change your log shipper configuration to avoid this time consuming pre-processing of your logs and take full control over the field names in your configuration.
If you use Sematext Docker Agent to ship logs, please use the latest version available on Docker Hub – it makes sure that the generated field names are compliant with Elasticsearch 2.x for all your containers logs.
Goodbye Kibana 3 and update to Kibana 4.3.1:
- Kibana 3 is not supported anymore by Elastic and does not work with Elasticsearch 2.x. As a consequence we had to remove Kibana 3 from Logsene. We know that we have big fans of Kibana 3 out there, but maybe it’s time to move to Kibana 4 … or Grafana might be an alternative for you – check out how to use Grafana with Logsene.
- Kibana 4.3.1 is now the default Kibana application behind the “Kibana” button. Please note that we automatically changed all index patterns to match your Logsene applications. The new index-pattern are not based on date formats anymore (i.e. not TOKEN_YYYY-MM-DD any more), the new index-pattern is simply TOKEN_*. This works without timeouts because Kibana 4.3.1 improved time range queries.
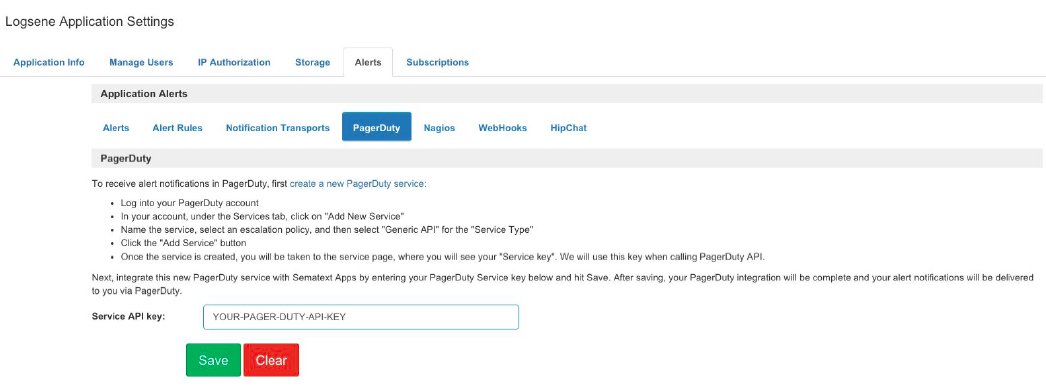
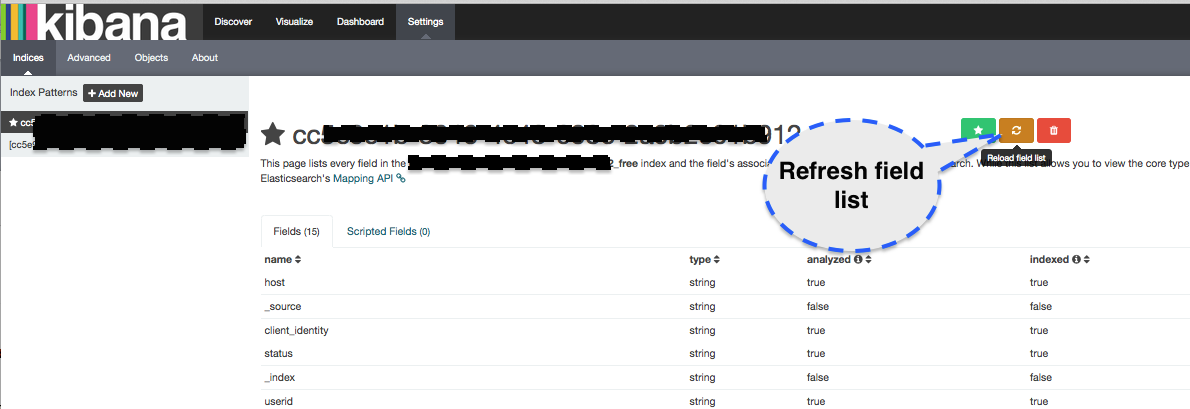
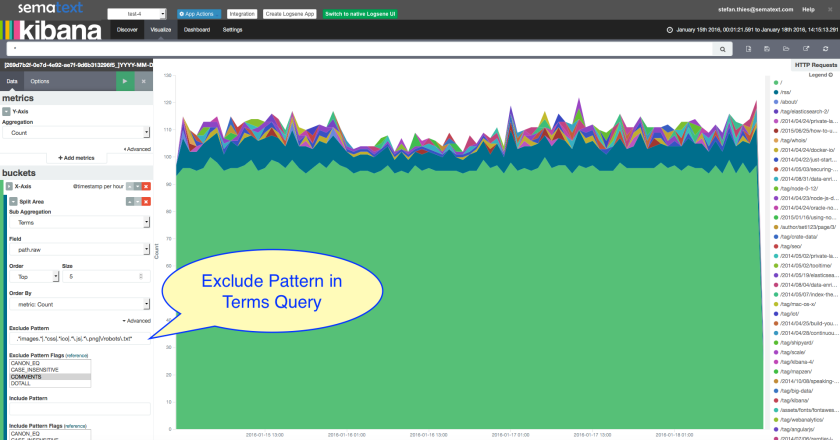
- Having issues with the new Kibana? Most of the warning or error messages in Kibana are caused by outdated mapping information. Please check this first before you get in touch with support@sematext.com. To refresh the mapping information open Kibana / Settings / Indices and press the orange “refresh” button:
Questions or Feedback?
If you have any questions or feedback for us, please contact us by email or using live chat in Logsene.

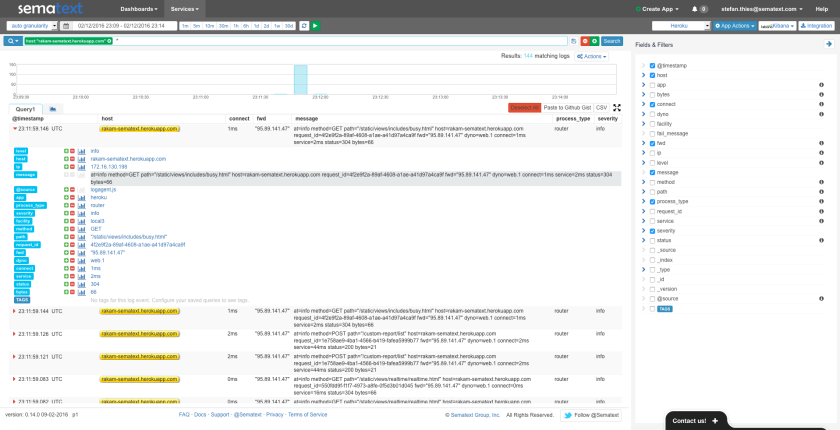

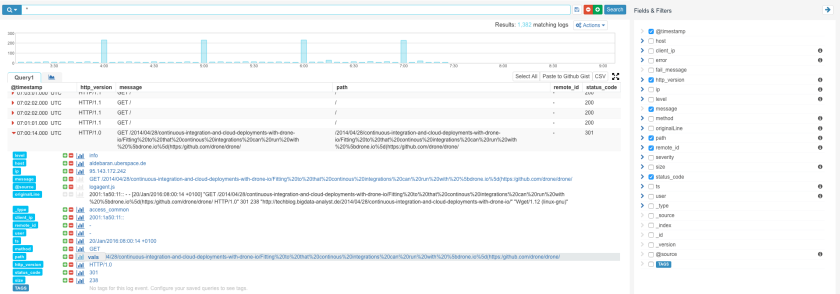
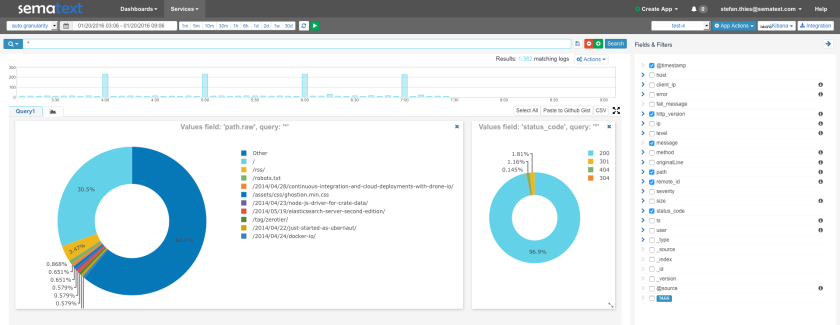

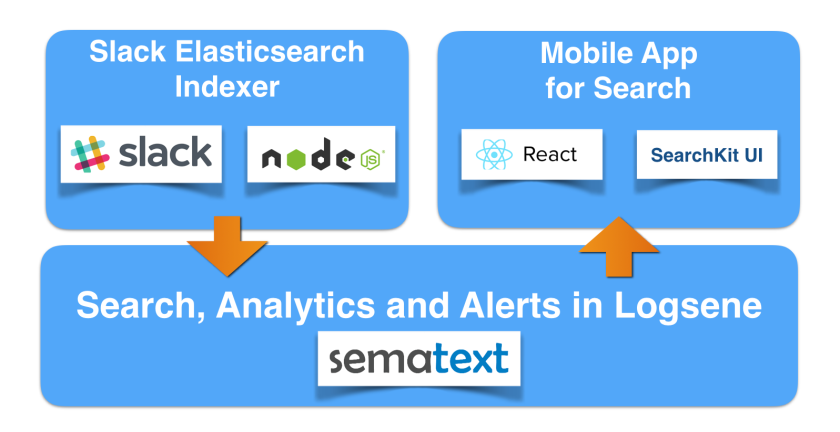
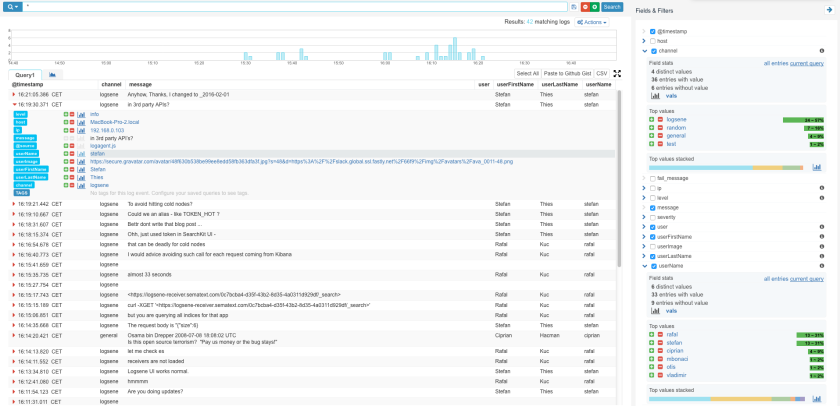
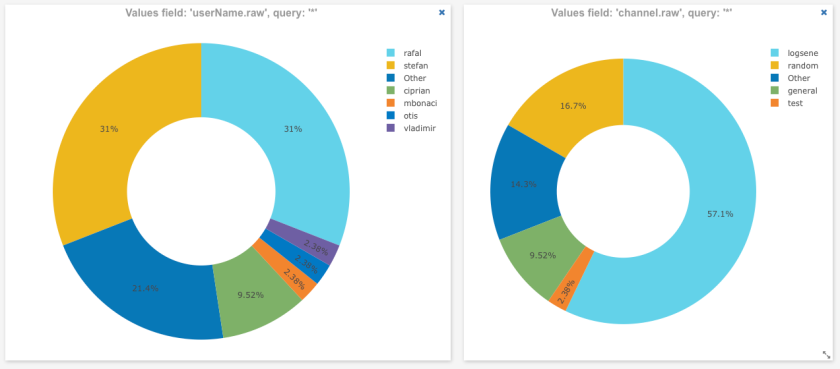
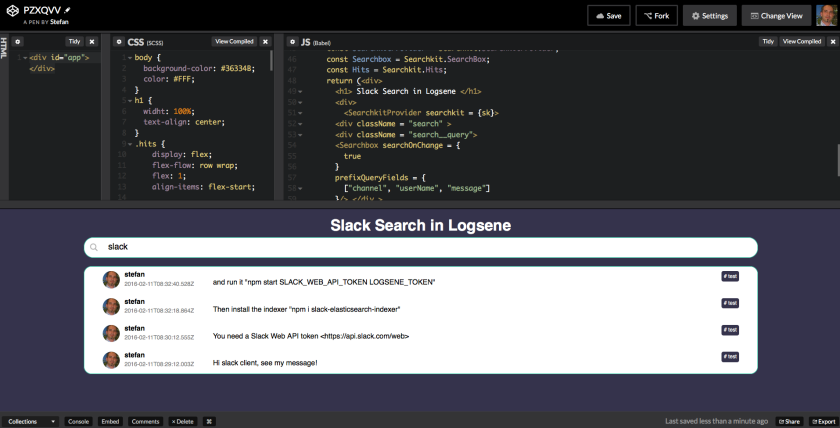
 While Logsene is great for alerts, analytics and Slack message search, as a general ‘data viewer’ the message rendering in Logsene does not show application-specific things like users’ profile pictures, which would allow much faster recognition of user messages. Thus, as our next step, we’ll create a simple Web Client with nice rendering of indexed Slack messages. Let’s see how this can be done very quickly using some cutting edge Web technology together with Logsene.
While Logsene is great for alerts, analytics and Slack message search, as a general ‘data viewer’ the message rendering in Logsene does not show application-specific things like users’ profile pictures, which would allow much faster recognition of user messages. Thus, as our next step, we’ll create a simple Web Client with nice rendering of indexed Slack messages. Let’s see how this can be done very quickly using some cutting edge Web technology together with Logsene.