[Note: this post was written by Sematext engineer Marko Bonaći]
In vino veritas, right? During a recent team gathering in Kraków, Poland, and after several yummy bottles of țuică, vișinată, żubrówka, diluted with some beer, the truth came out – even though we run Logsene, a log management service that you can think of as hosted ELK Stack, some of us still ssh into machines and grep logs! Whaaaaat!? What happened to eating our own dog food!? It turns out it’s still nice to be able to grep through logs, pipe to awk, sed, and friends. But that’s broken or at least inefficient — what do you do when you run multiple machines in a cluster of have several clusters? Kind of hard to grep all them logs, isn’t it? In the new world of containers this is considered an anti-pattern! We can do better! We can fix that!
Introducing Logsene CLI
Meet Logsene CLI, a command line tool used to search through all your logs from all your apps and servers in Logsene — from the console! Logsene CLI gives you the best of both worlds:
- have your logs off-site, in Logsene, where they will always be accessible and shareable with the team; and where you can visualize them, graph them, dashboard them, do anomaly detection on them, and get alerts on them
- have a powerful command-line log search tool you can combine with your favorite Linux tools: awk, grep, cut, sed, sort, head, tail, less, etc.
Logsene CLI is a Node.js app written by a self-proclaimed Node fanboy who, through coding Logsene CLI, became a real Node man and in the process grew a beard. The source code can be found on GitHub.
Logsene CLI in Action
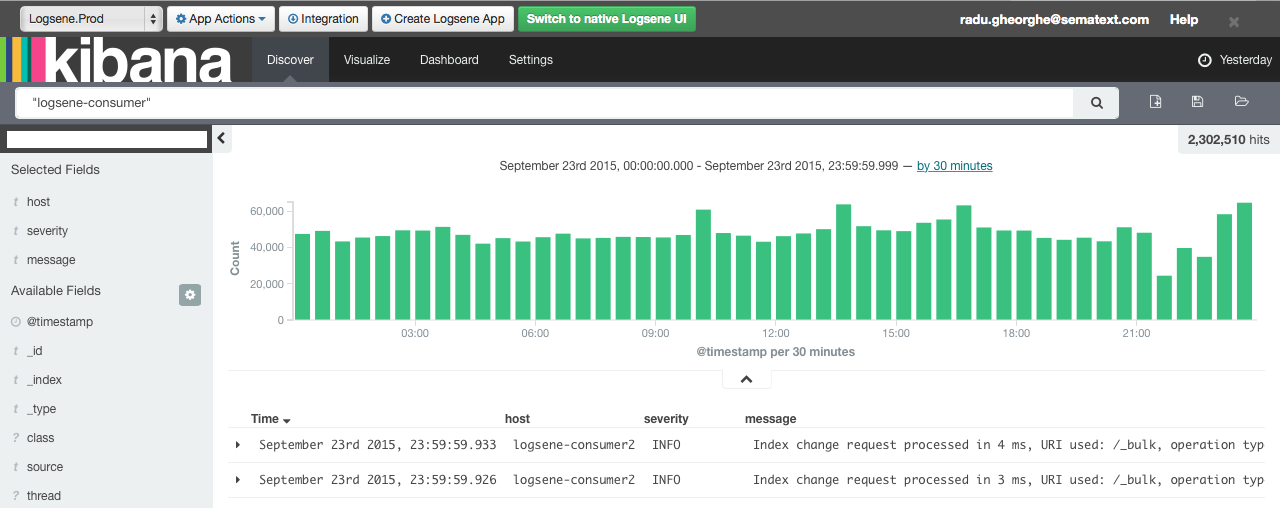
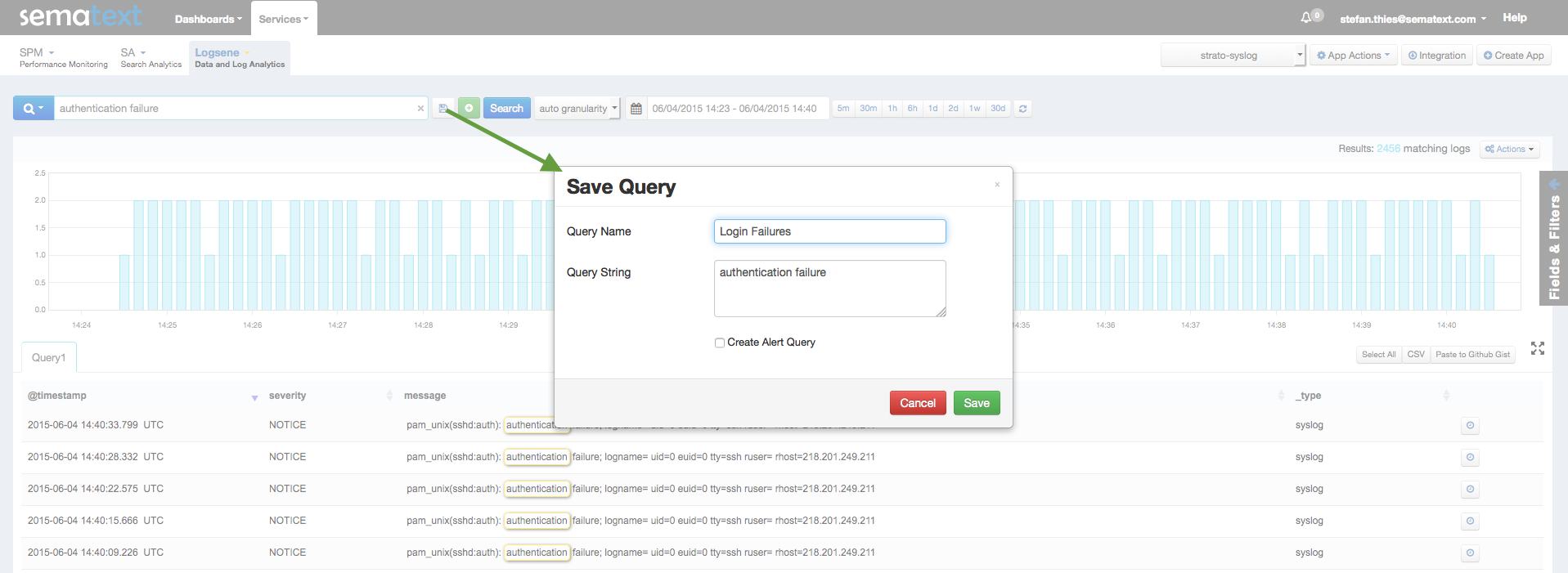
Here is what Logsene’s Web UI looks like:

See those two large input fields in the figure above — one for search query and the other for time range? Well, information that you’d normally enter via those fields is what Logsene CLI lets you enter, but from our beloved console. Let’s have a look.
Initial Authentication
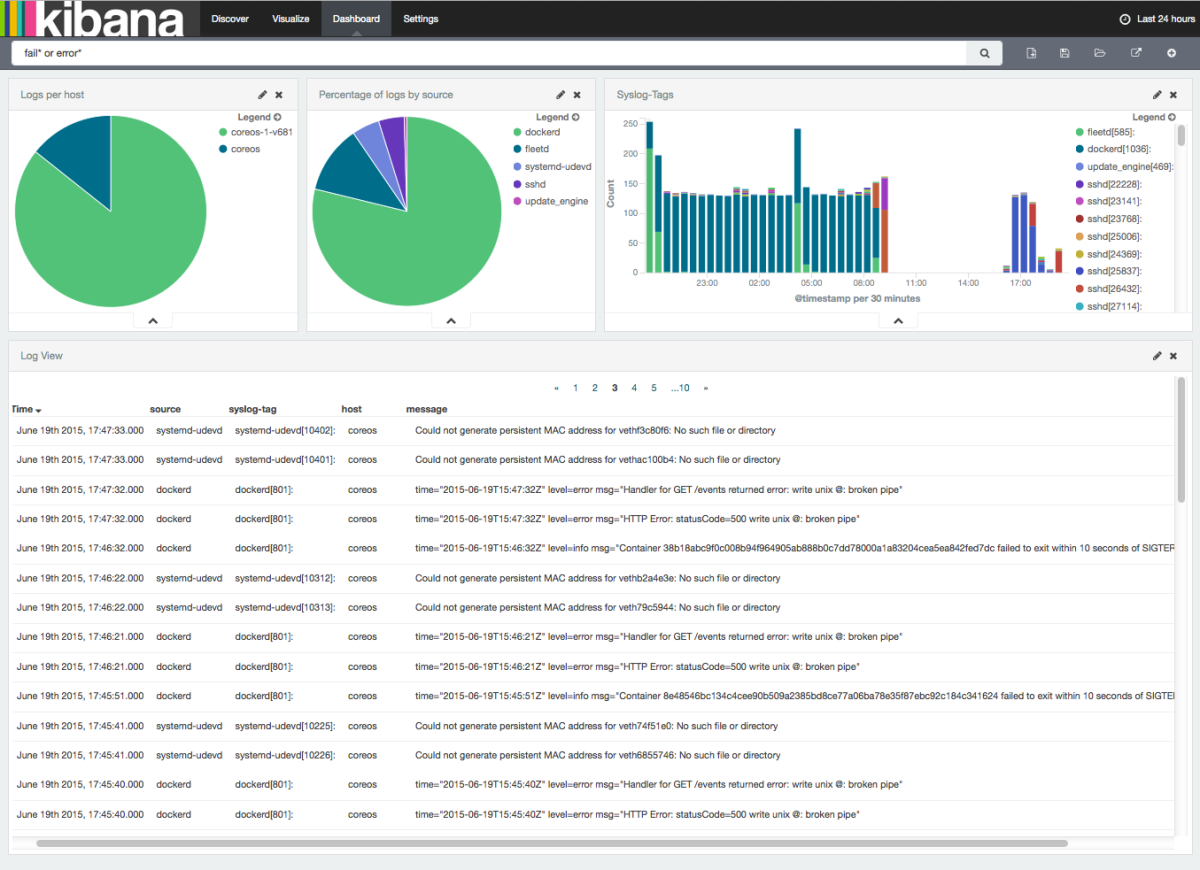
In order to use Logsene CLI, the only thing you need are your Sematext account credentials. When you run your first search, you’ll be prompted to authenticate and then you’ll choose the Logsene application you want to work with, as show below:

Usage Examples
Let’s start with a basic example using Web server logs.
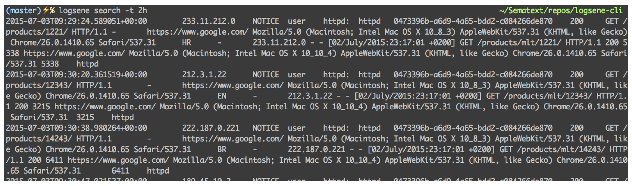
Say we want to retrieve all log entries from the last two hours (limited to first 200 events, which can be controlled with the -s parameter):
$ logsene search -t 2h

Now let’s combine Logsene CLI and awk. Say you want to find out the average response size during the last two hours. Before we do that, let’s also tell Logsene CLI to give us all matching events, not just first 200 by using the –default-size configuration setting without parameter:
$ logsene config set --default-size
Note that the default size limit is always in effect, unless explicitly changed in the configuration, like we just did. When set like this, in the configuration, the –default-size setting applies to the remainder of the current Logsene CLI session (times out after 30 minutes of inactivity). The other option is to use the -s parameter on a per-command basis, which works the same way, you either specify the maximum number of returned results or you just use -s without a quantifier to disable the limit altogether.
So back to average response time in the last two hours. You could do it like this:
$ logsene search -t 2h | awk 'BEGIN{sum=0;cnt=0}{sum+=$53;cnt++}END{print sum/cnt}'

There – with this one-liner you can see the average response size across all your web servers is 5557.1 bytes.
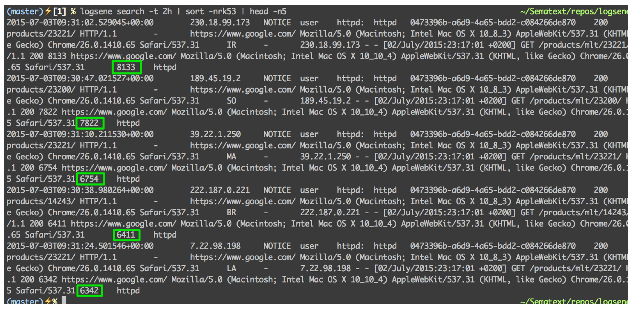
Next, let’s see how you’d combine log search/filtering with sort and head to get Top N reports, say five largest responses in the last two hours:
$ logsene search -t 2h | sort -nrk53 | head -n5

A little bit more realistic example — if your site were under a DoS attack, you might be interested in quickly seeing the top offenders. Here’s a one-liner that shows how to use the -f switch to specify which field(s) to return – field host, in this example:
$ logsene search -t 10m -f host | sort | uniq -c | sort -r | head -n20

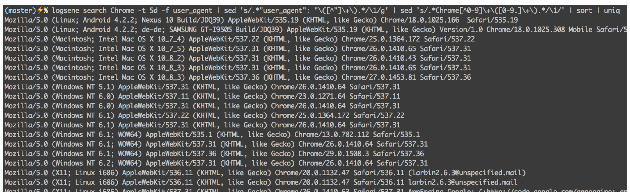
All examples so far were basically filtering by time. Let’s actually search out logs! Say you needed to get all versions of Chrome in the last 5 days:
$ logsene search Chrome -t 5d -f user_agent | \
sed 's/.*"user_agent": "\([^"]\+\).*/\1/g' | \
sed 's/.*Chrome[^0-9]\+\([0-9.]\+\).*/\1/' | sort | uniq
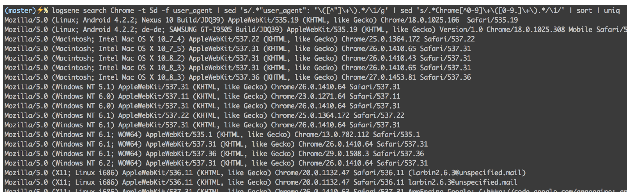
If you wanted to see the most popular versions of Chrome you’d just add count and sort. Let’s also add line numbers:
$ logsene search Chrome -t 5d -f user_agent | \
sed 's/.*"user_agent": "\([^"]\+\).*/\1/g' | \
sed 's/.*Chrome[^0-9]\+\([0-9.]\+\).*/\1/' | sort | uniq -c | sort -nr | nl
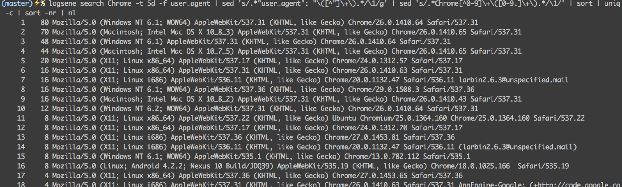
We’ve used Web access log for examples so far, but you can certainly send any logs/events to Logsene and search them.
In the next example we search for logs that contain either or both phrases we specified and that were created between last Sunday morning and now. Note that the “morning” part of the -t switch below translates to 06:00 (using whichever timezone your Logsene CLI is running in). Let’s also return up to 300 results, instead of the default 200.
$ logsene search "signature that validated" "signature is valid" -t "last Sunday morning" -s 300

Note how this does an OR query by default. Alternatively, you can use the -op AND switch to match only those logs that contain all given keywords or phrases.
Time Range Expressions
When searching through logs, it’s important to have a fine-grained time filtering capability. Here’s a quick rundown through a few ways to specify time filters.
To retrieve last hour of logs, use search command without parameters:
logsene search
Remember, if you have more than 200 logs in the last hour this will show only the first 200 logs, unless you explicitly ask for more of them using the -s switch. If you don’t want to limit the output and simply display all available logs, just use -s without any quantifiers, like this:
logsene search -s
Note: when you specify time without a timezone Logsene CLI uses the timezone of the computer it’s running on. If you want to use UTC, all you need to do is append Z to a timestamp (e.g. 2015-06-30T16:50:00Z).
To retrieve the last 2 hours of logs:
logsene search -t 2h
To retrieve logs since a timestamp:
logsene search -t 2015-06-30T16:48:22
The next five commands show how to specify time ranges with the -t parameter. Logsene CLI recognizes ranges by examining whether the -t parameter value contains the forward slash character (ISO-8601).
To retrieve logs between two timestamps:
logsene search -t 2015-06-30T16:48:22/2015-06-30T16:50:00
To retrieve logs in the next 10 minutes from a timestamp:
logsene search -t 2015-06-30T16:48:22/+10m
To retrieve logs in the 10 minutes up to a timestamp:
logsene search -t 2015-06-30T16:48:22/-10
Minutes are used by default, so you can just omit m.
To retrieve logs from between 5 and 6 hours ago:
logsene search -t 6h/+1h
To retrieve logs from between 6 and 7 hours ago:
logsene search -t 6h/-1h
Fork, yeah!
You can try Logsene CLI even if you don’t already have Sematext account. Opening a free, 30-day trial account is super simple. You’ll be set in less than 15 minutes to start playing with Logsene CLI. We won’t ask you for your credit card information (it’s not needed for a trial account, so why would we?). Try it!

The Logsene CLI source code can be found on GitHub.
Please ping us back with your impressions, comments, suggestions, … anything really. You can also reach us on Twitter @sematext, or the old-fashioned way, using e-mail. And we would be exceptionally happy if you filed an issue or submitted a pull request on GitHub. Enjoy!