More than two years ago we posted a recipe on how to centralize syslog in Elasticsearch in order to search and analyze them with Kibana, all by using only rsyslog. This works well, because rsyslog is fast and light, as we shown in later posts and recent presentations.
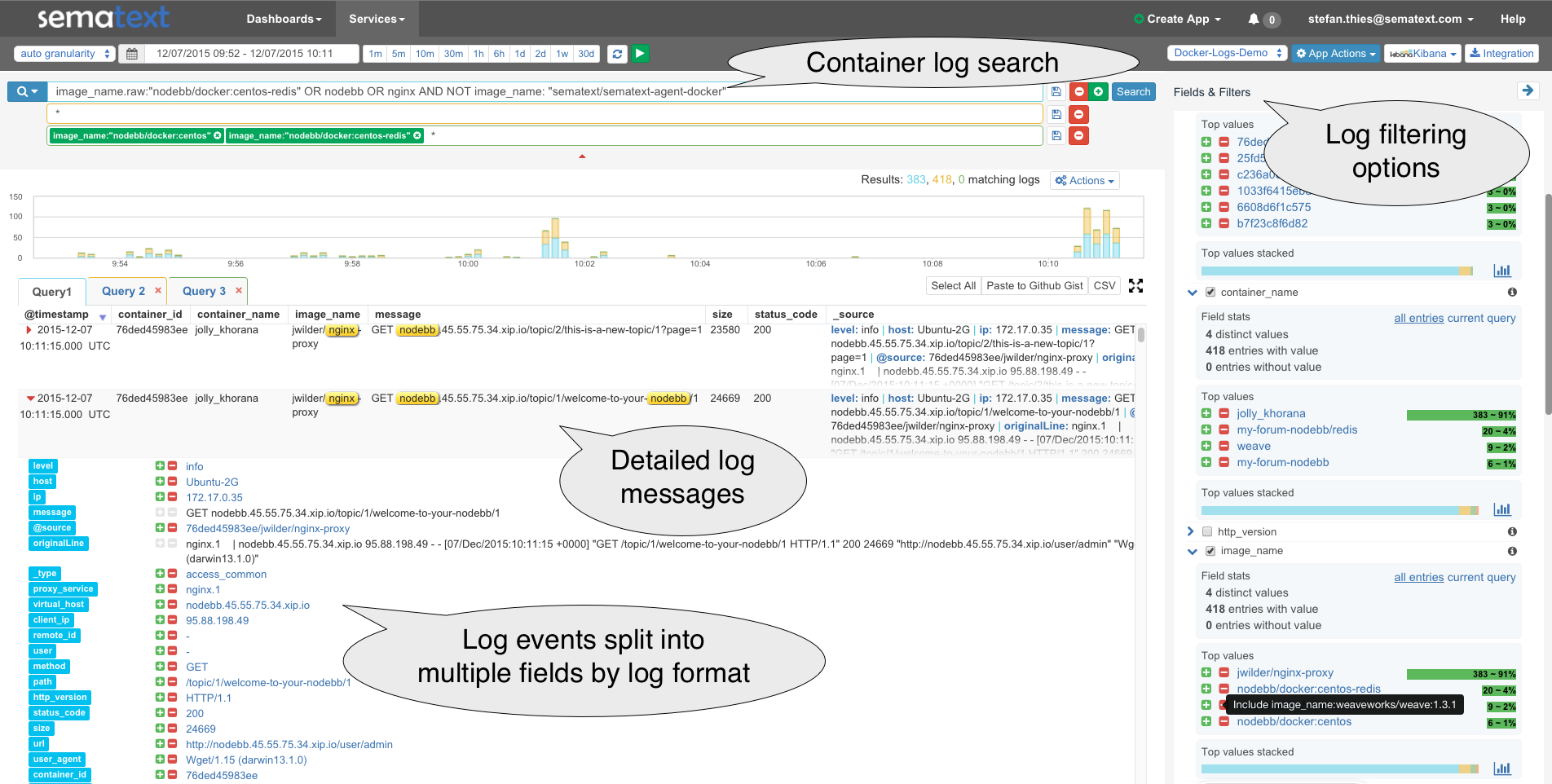
This recipe is about tailing Apache HTTPD logs with rsyslog, parsing them into structured JSON documents, and forwarding them to Elasticsearch (or our log analytics SaaS, Logsene, which exposes the Elasticsearch API). Having them indexed in a structured way will allow you to do better analytics with tools like Kibana:

We’ll also cover pushing system logs and how to buffer them properly, so it’s an updated, more complete recipe compared to the old one.
Getting the ingredients
Even though most distros already have rsyslog installed, it’s highly recommended to get the latest stable from the rsyslog repositories. This way you’ll benefit from the last two to five years of development (depending on how conservative your distro is). The packages you’ll need are:
With the ingredients in place, let’s start cooking a configuration. The configuration needs to do the following:
- load the required modules
- configure inputs: tailing Apache logs and system logs
- configure the main queue to buffer your messages. This is also the place to define the number of worker threads and batch sizes (which will also be Elasticsearch bulk sizes)
- parse common Apache logs into JSON
- define a template where you’d specify how JSON messages would look like. You’d use this template to send logs to Logsene/Elasticsearch via the Elasticsearch output
Loading modules
Here, we’ll need imfile to tail files, mmnormalize to parse them, and omelasticsearch to send them. If you want to tail the system logs, you’d also need to include imuxsock and imklog (for kernel logs).
# system logs
module(load="imuxsock")
module(load="imklog")
# file
module(load="imfile")
# parser
module(load="mmnormalize")
# sender
module(load="omelasticsearch")
Configure inputs
For system logs, you typically don’t need any special configuration (unless you want to listen to a non-default Unix Socket). For Apache logs, you’d point to the file(s) you want to monitor. You can use wildcards for file names as well. You also need to specify a syslog tag for each input. You can use this tag later for filtering.
input(type="imfile"
File="/var/log/apache*.log"
Tag="apache:"
)
NOTE: By default, rsyslog will not poll for file changes every N seconds. Instead, it will rely on the kernel (via inotify) to poke it when files get changed. This makes the process quite realtime and scales well, especially if you have many files changing rarely. Inotify is also less prone to bugs when it comes to file rotation and other events that would otherwise happen between two “polls”. You can still use the legacy mode=”polling” by specifying it in imfile’s module parameters.
Queue and workers
By default, all incoming messages go into a main queue. You can also separate flows (e.g. files and system logs) by using different rulesets but let’s keep it simple for now.
For tailing files, this kind of queue would work well:
main_queue(
queue.workerThreads="4"
queue.dequeueBatchSize="1000"
queue.size="10000"
)
This would be a small in-memory queue of 10K messages, which works well if Elasticsearch goes down, because the data is still in the file and rsyslog can stop tailing when the queue becomes full, and then resume tailing. 4 worker threads will pick batches of up to 1000 messages from the queue, parse them (see below) and send the resulting JSONs to Elasticsearch.
If you need a larger queue (e.g. if you have lots of system logs and want to make sure they’re not lost), I would recommend using a disk-assisted memory queue, that will spill to disk whenever it uses too much memory:
main_queue(
queue.workerThreads="4"
queue.dequeueBatchSize="1000"
queue.highWatermark="500000" # max no. of events to hold in memory
queue.lowWatermark="200000" # use memory queue again, when it's back to this level
queue.spoolDirectory="/var/run/rsyslog/queues" # where to write on disk
queue.fileName="stats_ruleset"
queue.maxDiskSpace="5g" # it will stop at this much disk space
queue.size="5000000" # or this many messages
queue.saveOnShutdown="on" # save memory queue contents to disk when rsyslog is exiting
)
Parsing with mmnormalize
The message normalization module uses liblognorm to do the parsing. So in the configuration you’d simply point rsyslog to the liblognorm rulebase:
action(type="mmnormalize"
rulebase="/opt/rsyslog/apache.rb"
)
where apache.rb will contain rules for parsing apache logs, that can look like this:
version=2
rule=:%clientip:word% %ident:word% %auth:word% [%timestamp:char-to:]%] "%verb:word% %request:word% HTTP/%httpversion:float%" %response:number% %bytes:number% "%referrer:char-to:"%" "%agent:char-to:"%"%blob:rest%
Where version=2 indicates that rsyslog should use liblognorm’s v2 engine (which is was introduced in rsyslog 8.13) and then you have the actual rule for parsing logs. You can find more details about configuring those rules in the liblognorm documentation.
Besides parsing Apache logs, creating new rules typically requires a lot of trial and error. To check your rules without messing with rsyslog, you can use the lognormalizer binary like:
head -1 /path/to/log.file | /usr/lib/lognorm/lognormalizer -r /path/to/rulebase.rb -e json
NOTE: If you’re used to Logstash’s grok, this kind of parsing rules will look very familiar. However, things are quite different under the hood. Grok is a nice abstraction over regular expressions, while liblognorm builds parse trees out of specialized parsers. This makes liblognorm much faster, especially as you add more rules. In fact, it scales so well, that for all practical purposes, performance depends on the length of the log lines and not on the number of rules. This post explains the theory behind this assuption, and there are already some preliminary tests to prove it as well (some of which we’ll present at Lucene Revolution). The downside is that you’ll lose some of the flexibility offered by regular expressions. You can still use regular expressions with liblognorm (you’d need to set allow_regex to on when loading mmnormalize) but then you’d lose a lot of the benefits that come with the parse tree approach.
Templates and actions
If you’re using rsyslog only for parsing Apache logs (and not system logs) and send your logs to Logsene, this bit is rather simple. Because by the time parsing ended, you already have all the relevant fields in the $!all-json variable, that you’ll use as a template:
template(name="all-json" type="list"){
property(name="$!all-json")
}
Then you an use this template to send logs to Logsene via the Elasticsearch API and using your Logsene application token as the index name:
action(type="omelasticsearch"
template="all-json" # use the template defined earlier
searchIndex="LOGSENE-APP-TOKEN-GOES-HERE"
searchType="apache"
server="logsene-receiver.sematext.com"
serverport="80"
bulkmode="on" # use the bulk API
action.resumeretrycount="-1" # retry indefinitely if Logsene/Elasticsearch is unreachable
)
Putting both Apache and system logs together
Finally, if you use the same rsyslog to parse system logs, mmnormalize won’t parse them (because they don’t match Apache’s common log format). In this case, you’ll need to pick the rsyslog properties you want and build an additional JSON template:
template(name="plain-syslog"
type="list") {
constant(value="{")
constant(value="\"timestamp\":\"") property(name="timereported" dateFormat="rfc3339")
constant(value="\",\"host\":\"") property(name="hostname")
constant(value="\",\"severity\":\"") property(name="syslogseverity-text")
constant(value="\",\"facility\":\"") property(name="syslogfacility-text")
constant(value="\",\"tag\":\"") property(name="syslogtag" format="json")
constant(value="\",\"message\":\"") property(name="msg" format="json")
constant(value="\"}")
}
Then you can make rsyslog decide: if a log was parsed successfully, use the all-json template. If not, use the plain-syslog one:
if $parsesuccess == "OK" then {
action(type="omelasticsearch"
template="all-json"
...
)
} else {
action(type="omelasticsearch"
template="plain-syslog"
...
)
}
And that’s it! Now you can restart rsyslog and get both your system and Apache logs parsed, buffered and indexed into Logsene. If you rolled your own Elasticsearch cluster, there’s one more step on the rsyslog side.
Time-based indices in your own Elasticsearch cluster
Logsene uses time-based indices out of the box, but in a local setup you’ll need to do this yourself. Such a design will give your cluster a lot more capacity due to the way Elasticsearch merges data in the background (we covered this in detail in our presentations at GeeCON and Berlin Buzzwords).
To make rsyslog use daily or other time-based indices, you need to define a template that builds an index name off the timestamp of each log. This is one that names them logstash-YYYY.MM.DD, like Logstash does by default:
template(name="logstash-index"
type="list") {
constant(value="logstash-")
property(name="timereported" dateFormat="rfc3339" position.from="1" position.to="4")
constant(value=".")
property(name="timereported" dateFormat="rfc3339" position.from="6" position.to="7")
constant(value=".")
property(name="timereported" dateFormat="rfc3339" position.from="9" position.to="10")
}
And then you’d use this template in the Elasticsearch output instead of a static index name (this also requires setting dynSearchIndex to on):
action(type="omelasticsearch"
template="all-json"
dynSearchIndex="on"
searchIndex="logstash-index"
searchType="apache"
server="MY-ELASTICSEARCH-SERVER"
bulkmode="on"
action.resumeretrycount="-1"
)
And now you’re really done, at least as far as rsyslog is concerned. For tuning Elasticsearch, have a look at our GeeCON and Berlin Buzzwords presentations. If you have additional questions, please let us know in the comments. And if you find this topic exciting, we’re happy to let you know that we’re hiring worldwide.