Heroku is a cloud platform based on a managed container system, with integrated data services and a powerful ecosystem for deploying and running modern apps. In this post we’ll show how you can ship logs from Heroku to Logsene, where you can then search your logs, get alerts based on log data, share log dashboards with your team, etc.
Watching Heroku logs in real-time in the terminal is easy using the “heroku logs” command, which is fine for ad-hoc log checks, but not for a serious production system. For production, you want to collect, parse, and ship logs to a log management system, where rich reporting and troubleshooting can be done. To do that the Heroku Log Drain setup is a must. What is a Heroku Log Drain and what does it do? In short, a Heroku Log Drain streams logs of your applications deployed on Heroku, either to a syslog or an HTTPS server.
When you have to deal with a large log volume a scalable log storage is required. This is where Logsene comes into play. Logsene provides a hosted ELK Stack and is available On Premises and in the Cloud. Logagent-js is a smart log parser written in node.js, taking advantage of async I/O to receive, parse and ship logs – including routing different application logs to different full text indices. We made the Logagent-js deployment on Heroku very easy and scaling out for a very high log volume is just one “heroku scale web=N” command away.
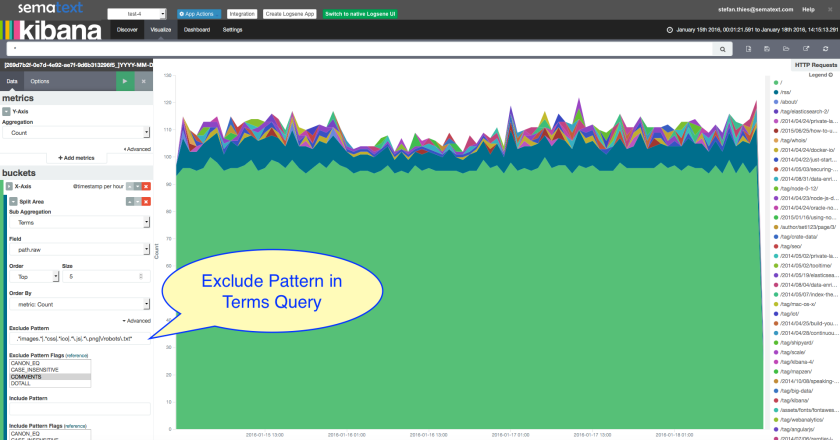
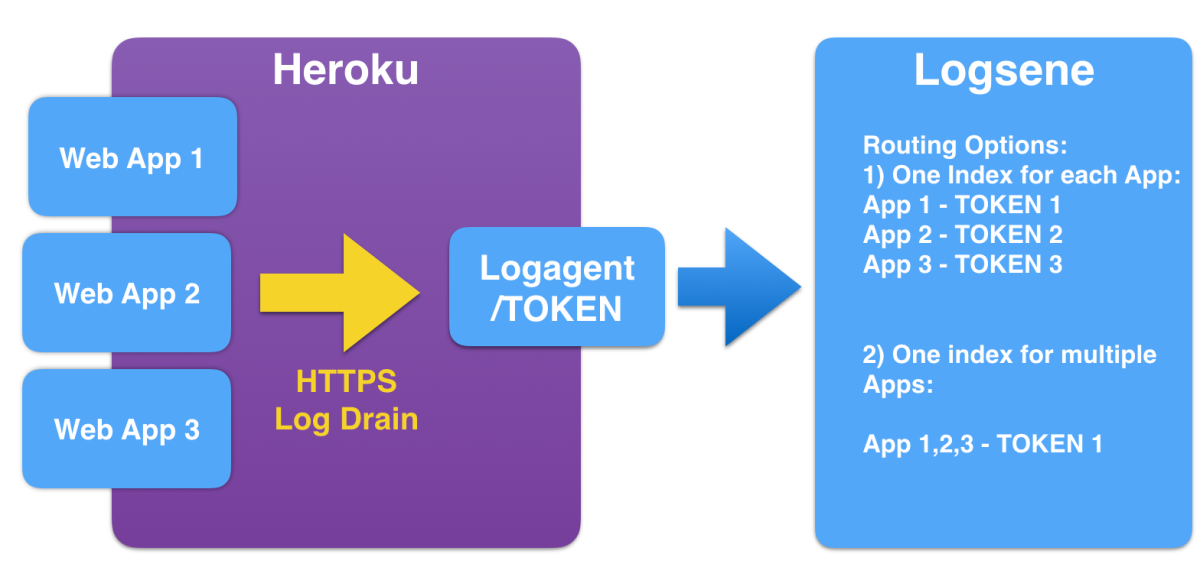
Let’s have a look at the architecture of this setup:
- Heroku Apps configured with a Heroku Log Drain
- logagent-js to receive, parse and ship logs
- Logsene as backend to store all your logs
Step 1 – Create your Logsene App
If you don’t have a Logsene account already simply get a free account and create a Logsene App. This will get you a Logsene Application Token, which we’ll use in Step 3.
Step 2 – Deploy Logagent-js to Heroku
We’ve prepared a “Deploy to Heroku” button – just click on it and enter a name for the deployed log agent in the Heroku UI:

Remember this name because we’ll need it later as the URL for the Log Drain.
Logagent-js can handle multiple Logsene tokens, which means it could be used for more than 1 Logsene app, simply addressed by /LOGSENE_TOKEN in the URL.
To run a short test without deploying logagent-js feel free to use the one we deployed for demos with the name “logsene-test”, reachable via https://logsene-test.herokuapp.com.
Step 3 – Configure Log Drain for your App
To configure the Heroku Log Drain we need the following information:
- The Logsene App Token
- The URL for the deployed logagent-js (e.g. logsene-app1.herokuapp.com)
- The Heroku App ID or name of your Application on Heroku (e.g. web-app-1 in the example below)
Then we can use the Heroku command line tool, for example like this:
heroku drains:add –app web-app-1 https://logsene-app1.herokuapp.com/25560d7b-ef59-4345-xxx-xxx
Or we could use the Heroku API to activate the Log Drain:
curl -n -X POST https://api.heroku.com/apps/web-app-1/log-drains \ -d '{"url": "https://logsene-app1.herokuapp.com/25560d7b-ef59-4345-xxx-xxx"}' \ -H "Content-Type: application/json" \ -H "Accept: application/vnd.heroku+json; version=3"
Step 4 – Watch your Logs in Logsene
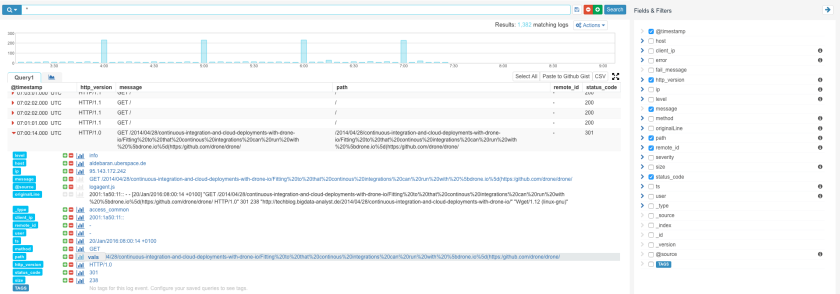
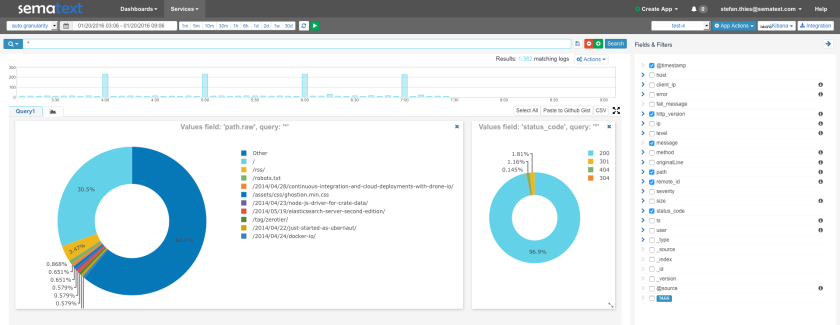
If you now access your App, Heroku should log your HTTP request and a few seconds later the logs will be visible in Logsene. And not in just any format! You’ll see PERFECTLY STRUCTURED HEROKU LOGS:
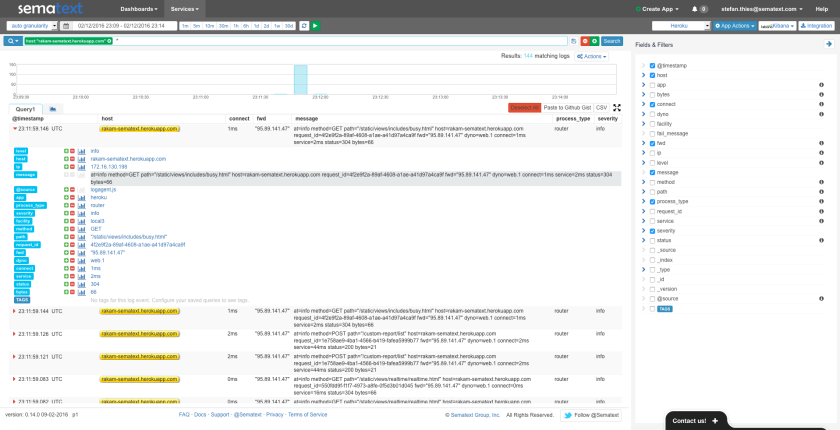
Enjoy!
Like what you saw here? To start with Logsene get a free account here or drop us an email, hit us on Twitter. Logagent-js is open-source – if you find any bugs please create an issue on Github with suggestions, questions or comments.