By default, Elasticsearch does a good job of figuring the type of data in each field of your logs. But if you like your logs structured like we do, you probably want more control over how they’re indexed: is time_elapsed an integer or a float? Do you want your tags analyzed so you can search for big in big data? Or do you need it not_analyzed, so you can show top tags via the terms aggregation? Or maybe both?
In this post, we’ll look at how to use index templates to manage multiple types of logs across multiple indices. Also, we’ll explain how to use logging tools (such as Logstash and rsyslog) to handle JSON logging and specify types.
Elasticsearch Mapping and Logs
As you may already know, to control these things in Elasticsearch you’ll need to define a mapping. This works similarly in Logsene, our log analytics SaaS, because it uses Elasticsearch and exposes its API.
With logs you’ll probably use time-based indices, because they scale better (in Logsene, for instance, you get daily indices). That said, to make sure the mapping you define today applies to the index you create tomorrow, you need to define it in an index template.
Managing Multiple Types
Mappings provide a nice abstraction when you have to deal with multiple types of structured data. Let’s say you have two apps generating logs of different structures: both have a timestamp field, but one recording logins has a user field, and another one recording purchases has an amount field.
To deal with this, you can define the timestamp field in the _default_ mapping which applies to all types. Then, in each type’s own mapping we’ll define fields unique to that mapping. The following snippet is an example that works with Logsene, provided that aaaaaaaa-bbbb-cccc-dddd-eeeeeeeeeeee is your Logsene app token. If you roll your own Elasticsearch, you can use whichever name you want, and make sure the template applies to your index pattern.
curl -XPUT 'logsene-receiver.sematext.com/_template/aaaaaaaa-bbbb-cccc-dddd-eeeeeeeeeeee_MyTemplate' -d '{
"template" : "aaaaaaaa-bbbb-cccc-dddd-eeeeeeeeeeee*",
"order" : 21,
"mappings" : {
"_default_" : {
"properties" : {
"timestamp" : { "type" : "date" }
}
},
"firstapp" : {
"properties" : {
"user" : { "type" : "string" }
}
},
"secondapp" : {
"properties" : {
"amount" : { "type" : "long" }
}
}
}
}'
Sending JSON Logs to Specific Types
When you send a document to Elasticsearch by using the API, you have to provide an index and a type. You can use an Elasticsearch client for your preferred language to log directly to Elasticsearch or Logsene this way. But I wouldn’t recommend this, because then you’d have to manage things like buffering if the destination is unreachable.
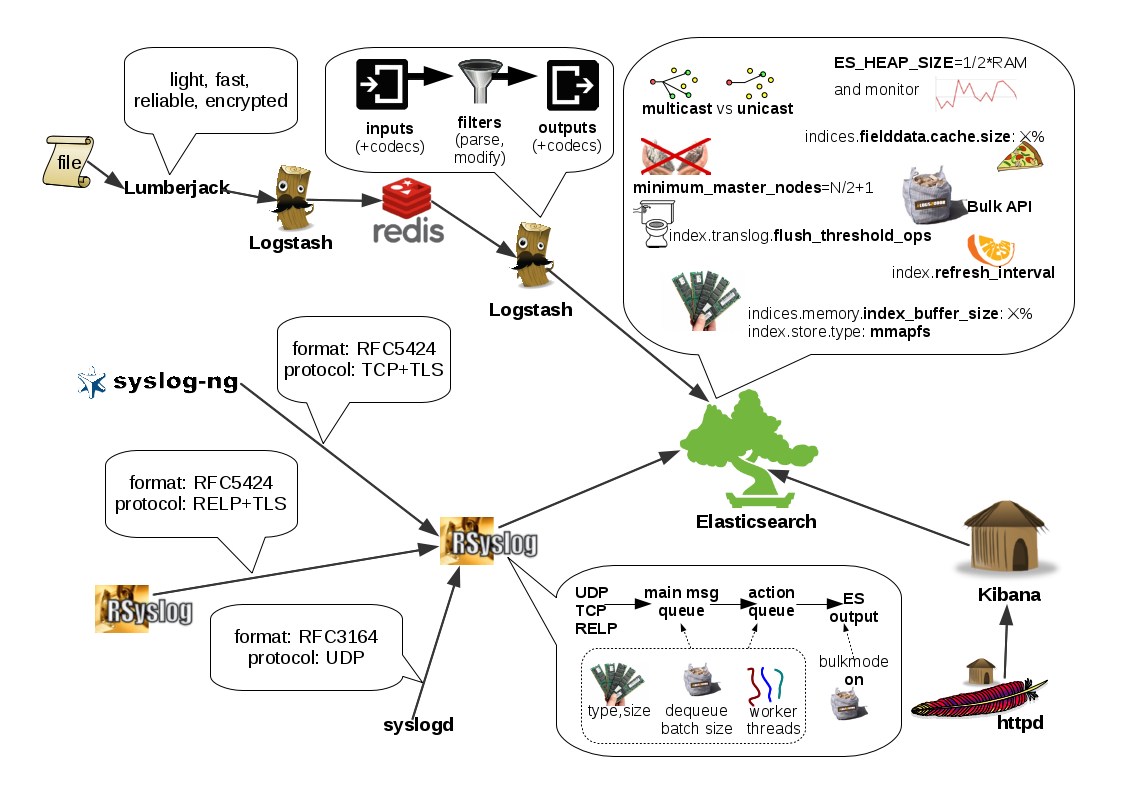
Instead, I’d keep my logging simple and use a specialized logging tool, such as Logstash or rsyslog to do the hard work for me. Logging to a file is usually the easiest option. It’s local, and you can have your logging tool tail the file and send contents over the network. I usually prefer sockets (like syslog) because they let me configure Logstash/rsyslog to:
– write events in a human format to a local file I can tail if I need to (usually in development)
– forward logs without hitting disk if I need to (usually in production)
Whatever you prefer, I think writing to local files or sockets is better than sending logs over the network from your application. Unless you’re willing to do a reliability trade-off and use UDP, which gets rid of most complexities.
Opinions aside, here’s a Logstash configuration for tailing a file with JSON logs separated by a newline. Here’s how you’d send those documents to Logsene via the Elasticsearch API:
input {
file {
path => "/var/log/test"
codec => "json"
}
}
output {
elasticsearch {
host => "logsene-receiver.sematext.com"
port => 80
index => "LOGSENE-APP-TOKEN-GOES-HERE"
index_type => "fileapp"
protocol => "http"
manage_template => false
}
}
Note how the JSON codec does the parsing here, instead of the more expensive and maintenance-heavy approach with grok that we’ve shown in an earlier post on getting started with Logstash. Some applications let you configure the log format, so you can make them write JSON (Apache httpd, for example).
If you want to send JSON over syslog, there’s the JSON-over-syslog (CEE) format that we detailed in a previous post. You can use rsyslog’s JSON parser module to take your structured logs and forward them to Logsene:
module(load="imuxsock") # can listen to local syslog socket
module(load="omelasticsearch") # can forward to Elasticsearch
module(load="mmjsonparse") # can parse JSON
action(type="mmjsonparse") # parse CEE-formatted messages
template(name="syslog-cee" type="list") { # Elasticsearch documents will contain
property(name="$!all-json") # all JSON fields that were parsed
}
action(
type="omelasticsearch"
template="syslog-cee" # use the template defined earlier
server="logsene-receiver.sematext.com"
serverport="80"
searchType="syslogapp"
searchIndex="LOGSENE-APP-TOKEN-GOES-HERE"
bulkmode="on" # send logs in batches
queue.dequeuebatchsize="1000" # of up to 1000
action.resumeretrycount="-1" # retry indefinitely (buffer) if destination is unreachable
)
To send a CEE-formatted syslog, you can run logger ‘@cee: {“amount”: 50}’ for example. Rsyslog would forward this JSON to Elasticsearch or Logsene via HTTP. Note that Logsene also supports CEE-formatted JSON over syslog out of the box if you want to use a syslog protocol instead of the Elasticsearch API.
Filtering by Type
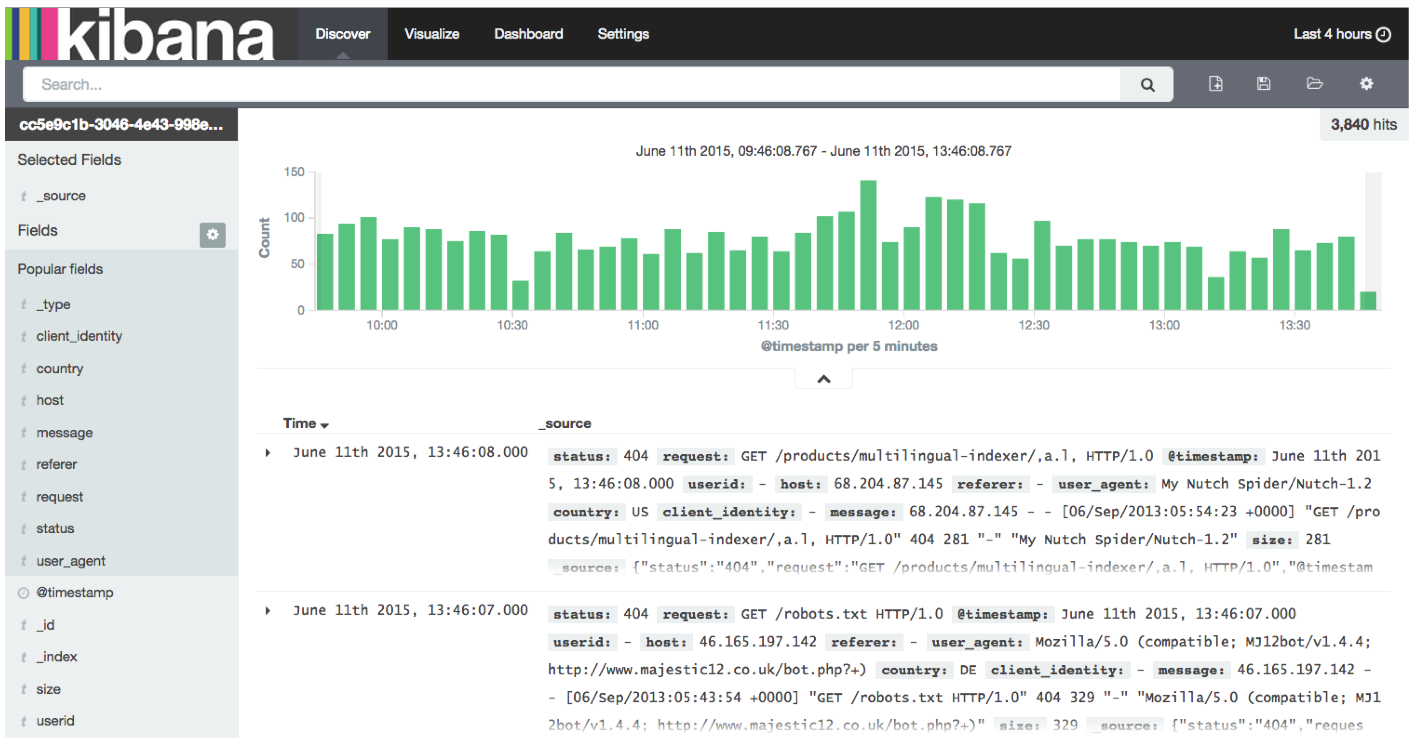
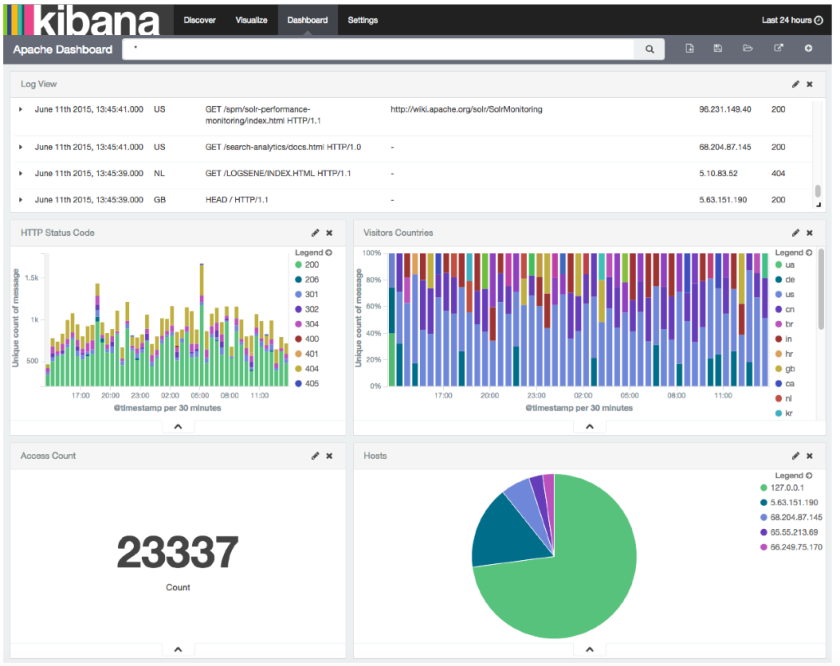
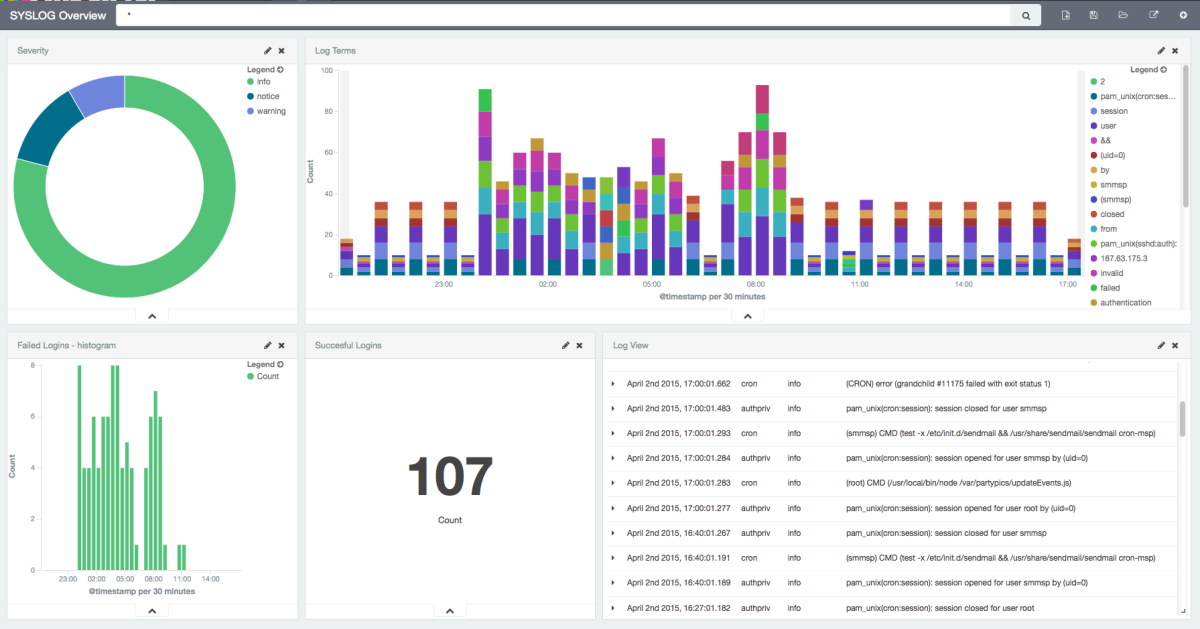
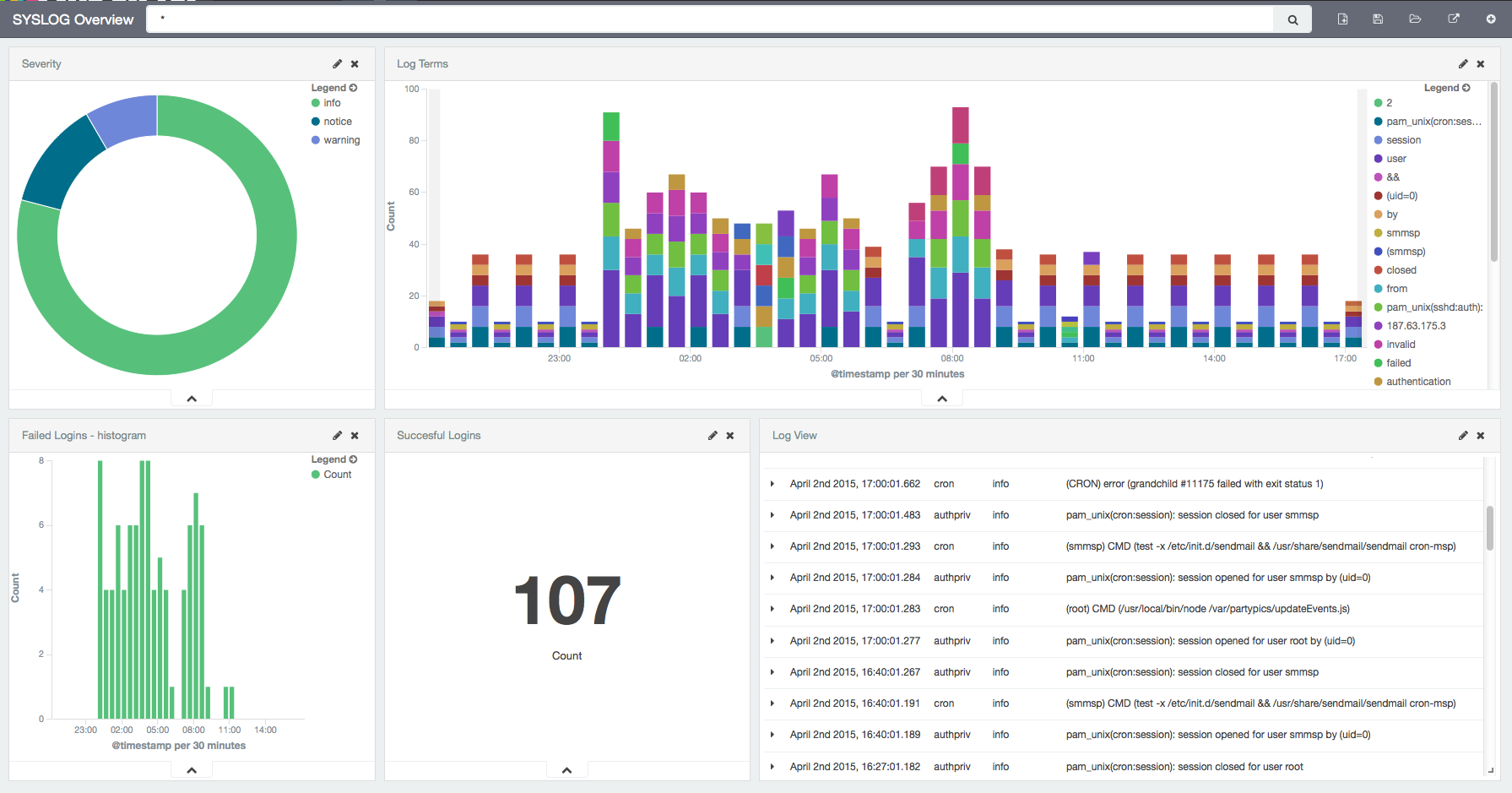
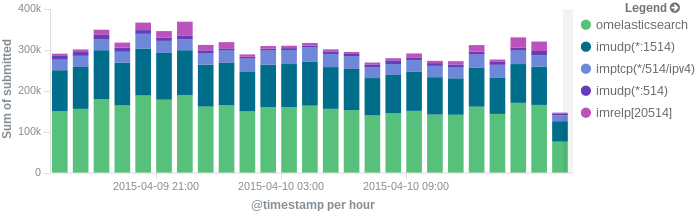
Once your logs are in, you can filter them by type (via the _type field) in Kibana:

However, if you want more refined filtering by source, we suggest using a separate field for storing the application name. This can be useful when you have different applications using the same logging format. For example, both crond and postfix use plain syslog.
If you’re looking for a place to send your logs to, check out Logsene!

 Kibana 4 automatically shows the “Discover” view and doesn’t require any setup – Logsene does everything for you! This means you can immediately start to build Queries, Visualizations, and Dashboards!
Kibana 4 automatically shows the “Discover” view and doesn’t require any setup – Logsene does everything for you! This means you can immediately start to build Queries, Visualizations, and Dashboards!