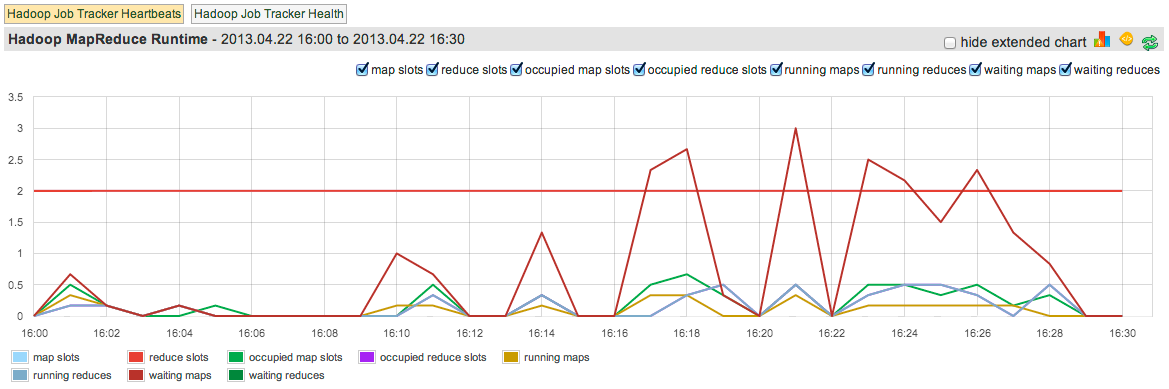
When it comes to Hadoop, they say you’ve got to monitor it and then monitor it some more. Since our own Performance Monitoring and Search Analytics services run on top of Hadoop, we figured it was time to add Hadoop performance monitoring to SPM. So here is a sneak peek at SPM for Hadoop. If you’d like to try it on your Hadoop cluster, we’ll be sending invitations soon and you can get on the private beta list starting today!
In the mean time, here is a small sample of pretty self-explanatory reports from SPM for Hadoop, so you can get a sense of what’s available. There are, of course, a number of other Hadoop-specific reports included, as well as server reports, filtering, alerting, multi-user support, report sharing, etc. etc.
Please don’t forget to tell us what else would you like us to monitor – select your candidates – and if you like what you see and want a good monitoring tool for your Hadoop cluster, please sign up for private beta now.
Click on any graph to see it in its full size and high quality.
In HBase world, RegionServer hotspotting is a common problem. We can describe this problem with a single sentence: while writing records with sequential row keys allows the most efficient reading of data range given the start and stop keys, it causes undesirable RegionServer hotspotting at write time. In this 2-part post series we’ll discuss the problem and show you how to avoid this infamous problem.
Problem Description
Records in HBase are sorted lexicographically by the row key. This allows fast access to an individual record by its key and fast fetching of a range of data given start and stop keys. There are common cases where you would think row keys forming a natural sequence at write time would be a good choice because of types of queries that will fetch the data later. For example, we may want to associate each record with a timestamp so that later we can fetch records from a particular time range. Examples of such keys are:
time-based format: Long.MAX_VALUE – new Date().getTime()
increasing/decreasing sequence: ”001”, ”002”, ”003”,… or ”499”, ”498”, ”497”, …
But writing records with such naive keys will cause hotspotting because of how HBase writes data to its Regions.
RegionServer Hotspotting
When records with sequential keys are being written to HBase all writes hit one Region. This would not be a problem if a Region was served by multiple RegionServers, but that is not the case – each Region lives on just one RegionServer. Each Region has a pre-defined maximal size, so after a Region reaches that size it is split in two smaller Regions. Following that, one of these new Regions takes all new records and then this Region and the RegionServer that serves it becomes the new hotspot victim. Obviously, this uneven write load distribution is highly undesirable because it limits the write throughput to the capacity of a single server instead of making use of multiple/all nodes in the HBase cluster. The uneven load distribution can be seen in Figure 1. (chart courtesy of SPM for HBase):
Figure 1. HBase RegionServer hotspotting
We can see that while one server was sweating trying to keep up with writes, others were “resting”. You can find some more information about this problem in HBase Reference Guide.
Solution Approach
So how do we solve this problem? The cases discussed here assume that we don’t have all data we want to write to HBase all at once, but rather that the data are arriving continuously. In case of bulk import of data into HBase the best solutions, including those that avoid hotspotting, are described in bulk load section of HBase documentation. However, if you are like us at Sematext, and many organizations nowadays are, the data keeps streaming in and needs processing and storing. The simplest way to avoid single RegionServer hotspotting in case of continuously arriving data would be to simply distribute writes over multiple Regions by using random row keys. Unfortunately, this would compromise ability to do fast range scans using start and stop keys. But that is not the only solution. The following simple approach solves the hotspotting issue while at the same time preserving the ability to fetch data by start and stop key. This solution, mentioned multiple times on HBase mailing lists and elsewhere is to salt row keys with a prefix. For example, consider constructing the row key using this:
For the visual types among us, that may result in keys looking as shown in Figure 2.
Figure 2. HBase row key prefix salting
Here we have:
index is the numeric (or any sequential) part of the specific record/row ID that we later want to use for record fetching (e.g. 1, 2, 3 ….)
BUCKETS_NUMBER is the number of “buckets” we want our new row keys to be spread across. As records are written, each bucket preserves the sequential notion of original records’ IDs
original_key is the original key of the record we want to write
new_row_key is the actual key that will be used when writing a new record (i.e. “distributed key” or “prefixed key”). Later in the post the “distributed records” term is used for records which were written with this “distributed key”.
Thus, new records will be split into multiple buckets, each (hopefully) ending up in a different Region in the HBase cluster. New row keys of bucketed records will no longer be in one sequence, but records in each bucket will preserve their original sequence. Of course, if you start writing into an empty HTable, you’ll have to wait some time (depending on the volume and velocity of incoming data, compression, and maximal Region size) before you have several Regions for a table. Hint: use pre-splitting feature for the new table to avoid the wait time. Once writes using the above approach kick in and start writing to multiple Regions your “slaves load” chart should look better.
Since data is placed in multiple buckets during writes, we have to read from all of those buckets when doing scans based on “original” start and stop keys and merge data so that it preserves the “sorted” attribute. That means BUCKETS_NUMBER more Scans and this can affect performance. Luckily, these scans can be run in parallel and performance should not degrade or might even improve — compare the situation when you read 100K sequential records from one Region (and thus one RegionServer) with reading 10K records from 10 Regions and 10 RegionServers in parallel!
Get/Delete
To get or delete a single record by original key may need to perform 1 or up to BUCKETS_NUMBER Get operations depending on the logic we used for prefix generation. E.g. when using “static” hash as prefix, given the original key we may precisely identify the prefixed key. In case we used random prefix we will have to perform Get for each of the possible buckets. The same goes for Delete operations.
MapReduce Input
Since we still want to benefit from data locality, the implementation of feeding “distributed” data to a MapReduce job will likely break the order in which data comes to mappers. This is at least true for the current HBaseWD implementation (see below). Each map task will process data for a particular bucket. Of course, records will be in same order based on original keys within a bucket. However, since two records which were meant to be “near each other” based on their original key may have fallen into different buckets, the will be fed to different map tasks. Thus, if the mapper assumes records come in the strict/original sequence, we will be hurt, since the order will be preserved only within each bucket, but not globally.
Increased Number of Map Tasks
When using data (written using the suggested approach) as a MapReduce input (with start and/or stop key provided) the splits number will likely to be increased (depends on the implementation). For current HBaseWD implementation you’ll get BUCKETS_NUMBER times more splits compared to “regular” MapReduce with same parameters. This is due to the same logic for data selection as with simple Scan operation, as described above. As the result, MapReduce jobs will have BUCKETS_NUMBER times more map tasks. This should not decrease performance if BUCKETS_NUMBER is reasonably not too high (when MR job initialization & cleanup work takes more time than processing itself). Moreover, in many use-cases having many more mappers helps improve performance. Many users reported more mappers having a positive impact given that standard HTable input based MapReduce job usually has too few map tasks (one per Region) which cannot be changed without extra coding.
Another strong signal the suggested approach and its implementation could help is if in your application, in addition to writing records with sequential keys, the application also continuously processes newly written data delta using MapReduce . In such use-cases when data is written sequentially (not using any artificial distribution) and is being processed relatively frequently, the delta to be processed resides in just a few Regions (or perhaps in even just one Region if the write load is not high, if maximal Region size is high, and processing batches are very frequent).
Solution Implementation: HBaseWD
We implemented the solution described above and open-sourced it as a small HBaseWD project. We say small because HBaseWD is really self-contained and really simple to integrate into an existing code due to support for native HBase client API (see examples below). HBaseWD project was first presented at BerlinBuzzwords 2011(video) and is currently used in a number of production systems.
Configuring Distribution
Simple Even Distribution
Distributing records with sequential keys to be distributed in up to Byte.MAX_VALUE buckets (single byte is added in front of a key):
byte bucketsCount = (byte) 32; // distributing into 32 buckets
RowKeyDistributor keyDistributor = new RowKeyDistributorByOneBytePrefix(bucketsCount);
Put put = new Put(keyDistributor.getDistributedKey(originalKey));
... // add values
hTable.put(put);
Hash-Based Distribution
Another useful RowKeyDistributor is RowKeyDistributorByHashPrefix. Please see example below. It creates the “distributed key” based on original key value so that later when you have original key and want to update the record you can calculate distributed key without having to call HBase (too see what bucket it is in). Or, you can perform a single Get operation when original key is known (instead of reading from all buckets).
AbstractRowKeyDistributor keyDistributor =
new RowKeyDistributorByHashPrefix(
new RowKeyDistributorByHashPrefix.OneByteSimpleHash(15));
You can use your own hashing logic here by implementing this simple interface:
HBaseWD is designed to be flexible especially when it comes to supporting custom row key distribution approaches. In addition to the above mentioned ability to implement custom hashing logic to be used with RowKeyDistributorByHashPrefix, one can define custom row key distribution logic by extending AbstractRowKeyDistributor abstract class whose interface is super simple:
public abstract class AbstractRowKeyDistributor implements Parametrizable {
public abstract byte[] getDistributedKey(byte[] originalKey);
public abstract byte[] getOriginalKey(byte[] adjustedKey);
public abstract byte[][] getAllDistributedKeys(byte[] originalKey);
... // some utility methods
}
Common Operations
Scan
Performing a range scan over data:
Scan scan = new Scan(startKey, stopKey);
ResultScanner rs = DistributedScanner.create(hTable, scan, keyDistributor);
for (Result current : rs) {
...
}
Configuring MapReduce Job
Performing MapReduce job over the data chunk specified by Scan:
Configuration conf = HBaseConfiguration.create();
Job job = new Job(conf, "testMapreduceJob");
Scan scan = new Scan(startKey, stopKey);
TableMapReduceUtil.initTableMapperJob("table", scan,
RowCounterMapper.class, ImmutableBytesWritable.class, Result.class, job);
// Substituting standard TableInputFormat which was set in
// TableMapReduceUtil.initTableMapperJob(...)
job.setInputFormatClass(WdTableInputFormat.class);
keyDistributor.addInfo(job.getConfiguration());
What’s Next?
In the next post we’ll cover:
Integration into already running production systems
The biggest announcement of the year: Apache Hadoop 0.21.0 released and is available for download here. Over 1300 issues have been addressed since 0.20.2; you can find details for Common, HDFS and MapReduce. Note from Tom White who did an excellent job as a release manager: “Please note that this release has not undergone testing at scale and should not be considered stable or suitable for production. It is being classified as a minor release, which means that it should be API compatible with 0.20.2.”. Please find a detailed description of what’s new in 0.21.0 release here.
Community trends & news:
New branch hadoop-0.20-security is being created. Apart from the security features, which are in high demand, it will include improvements and fixes from over 12 months of work by Yahoo!. The new security features are going to be a very valuable and welcome contribution (also discussed before).
A thorough discussion about approaches of backing up HDFS data in this thread.
Hive voted to become Top Level Apache Project (TLP) (also here). Note that we’ll keep Hive under Search-Hadoop.com even after Hive goes TLP.
Pig voted to become TLP too (also here). Note that we’ll keep Pig under Search-Hadoop.com even after Pig goes TLP.
Tip: if you define a Hadoop object (e.g. Partitioner, as implementing Configurable, then its setConf() method will be called once, right after it gets instantiated)
For those new to ZooKeeper and pressed for time, here you can find the shortest ZooKeeper description — only 4 sentences short!
avro-scala-compiler-plugin: aimed to auto-generate Avro serializable classes based on some simple case class definitions
FAQ:
How to programatically determine the names of the files in a particular Hadoop/HDFS directory?
Use FileSystem & FileStatus API. Detailed examples are in this thread.
How to restrict HDFS space usage?
Please, refer to HDFS Quotas Guide.
How to pass parameters determined at run-time (i.e. not hard-coded) to Hadoop objects (like Partitioner, Writable, etc.)?
One option is to define a Hadoop object as implementing Configurable. In this case its setConf() method will be called once, right after it gets instantiated and you can use “native” Hadoop configuration for passing parameters you need.
This is the first post in the Nutch Digest series and a little introduction to Nutch seems in order. Nutch is a multi-threaded and, more importantly, a distributed Web crawler with distributed content processing (parsing, filtering), full text indexer and a search runtime. Nutch is at version 1.0 and community is now working towards a 1.1. release. Nutch is a large scale, flexible Web search engine, which includes several types of operations. In this post we’ll present new features and mailing list discussion as we describe each of these operations.
Crawling
Nutch starts crawling from a given “seed list” (a list of seed URLs) and iteratively follows useful/interesting outlinks, thus expanding its link database. When talking about Nutch as a crawler it is important to distinguish between two different approaches: focused or vertical crawling and whole Web or wide crawling. Each approach has a different set-up and issues which need to be addressed. At Sematext we’ve done both vertical and wide crawling.
When using Nutch at large scale (whole Web crawling and dealing with e.g. billions of URLs), generating a fetchlist (a list of URLs to crawl) from crawlDB (the link database) and updating crawlDB with new URLs tends to take a lot of time. One solution is to limit such operations to a minimum by generating several fetchlists in one parse of the crawlDB and then update the crawlDb only once on several segments (set of data generated by a single fetch iteration). Implementation of a Generator that generates several fetchlists at was created in NUTCH-762. Whether this feature will be included in 1.1 release and when will version 1.1 be released, check here.
One more issue related to whole Web crawling which often pops up on the Nutch mailing list is an authenticated websites crawling, so here is wiki page on this subject.
When using Nutch for vertical/focused crawls, one often ends up with a very slow fetch performance at the end of each fetch iteration. An iteration typically starts with high fetch speed, but it drops significantly over time and keeps dropping, and dropping, and dropping. This is known problem. It is caused by the fetch run having a small number of sites, some of which may have a lot more pages than others, and may be much slower than others. Crawler politeness, which means it will politely wait before hitting the same domain again, combined with the fact that the number of distinct domains from fetchlist often drops rapidly during one fetch causes fetcher to wait a lot. More on this and overall Fetcher2 performance (which is a default fetcher in Nutch 1.0) you can find NUTCH-721.
To be able to support whole Web crawling, Nutch needs also needs to have scalable data processing mechanism. For this purpose Nutch uses Hadoop’s MapReduce processing and HDFS for storage.
Content storing
Nutch uses Hadoop’s HDFS as a fully distributed storage which creates multiple replicas of data blocks and distributes them on compute nodes throughout a cluster to enable reliable and fast computations even on large data volumes. Currently, Nutch is using Hadoop 0.20.1, but will be upgrading to Hadoop 0.20.2. in version 1.1.
In this NUTCH-650 you can find out more about the ongoing effort (and progress) to use HBase as Nutch storage backend. This should simplify Nutch storage and make URL/page processing work more efficient due to the features of HBase (data is mutable and indexed by keys/columns/timestamps).
Content processing
As we noted before, Nutch does a lot of content processing, like parsing (parsing downloaded content to extract text) and filtering (extracting only URLs which match filtering requirements). Nutch is moving away from its own processing tools and delegating content parsing and MimeType detection to Tika by use of Tika plugin, you can read more NUTCH-766.
Indexing and Searching
Nutch uses Lucene for indexing, currently version 2.9.1, but pushing to upgrade Lucene to 3.0.1. Nutch 1.0 can also index directly to Solr, becuse of Nutch-Solr integration. More on this and how using Solr with Nutch worked before Solr-Nutch integration you can find here. This integration now upgrades to Solr 1.4, because Solr 1.4 has a StreamingUpdateSolrServer which simplifies the way docs are buffered before sending to the Solr instance. Another improvement in this integration was a change to SolrIndexer to commit only once after all reducers have finished, NUTCH-799.
Some of patches discussed here and a number of other high quality patches were contributed by Julien Nioche who was added as a Nutch committer in December 2009.
One more thing, keep an eye on an interesting thread about Nutch becoming a Top Level Project (TLP) at Apache.