Docker Swarm is a cluster manager for Docker. When accessed via the Docker API by Docker API Clients or Docker command line tools, a Docker Swarm cluster looks just like a single Docker Host. Docker Swarm distributes containers to multiple nodes using various deployment strategies in the cluster scheduler.
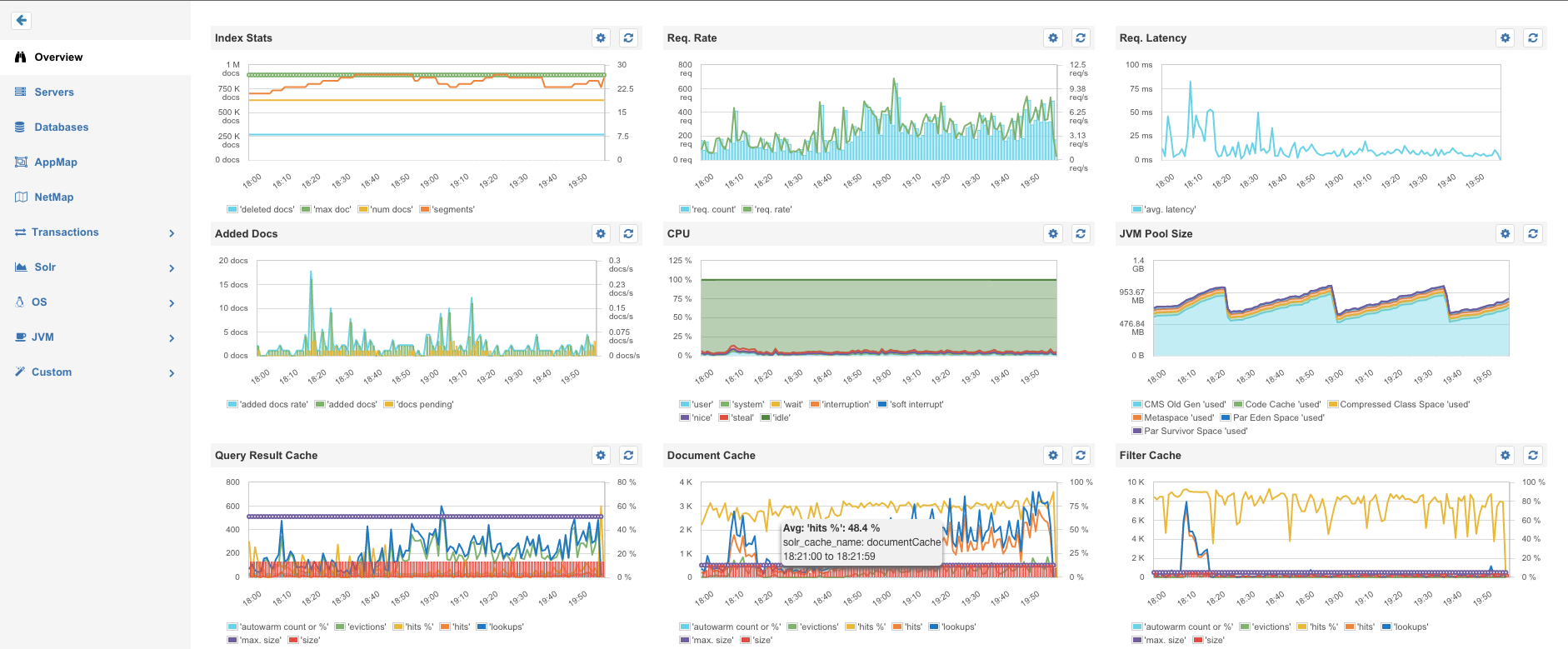
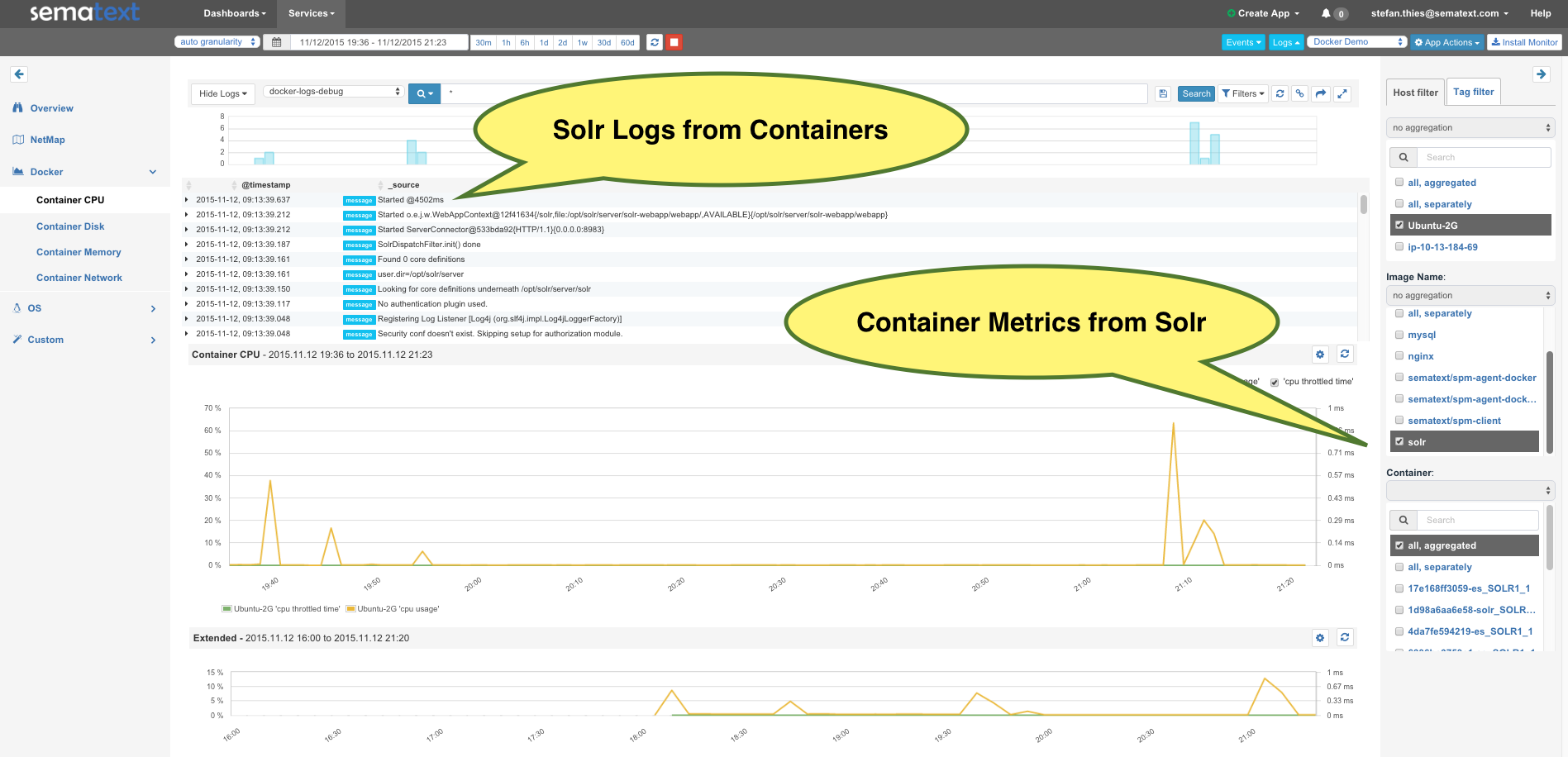
Having in mind that a Swarm cluster looks like a single Docker Host from the API point of view, it should be very easy to monitor Docker Swarm with existing Docker monitoring tools! Connecting a monitoring agent to the Swarm Master API endpoint should do the job, right? The Sematext Docker Agent could simply collect all container metrics, events and all logs from the Swarm Master – should be a piece of cake. Hm, but could there a gotcha? It turns out there is more than one:
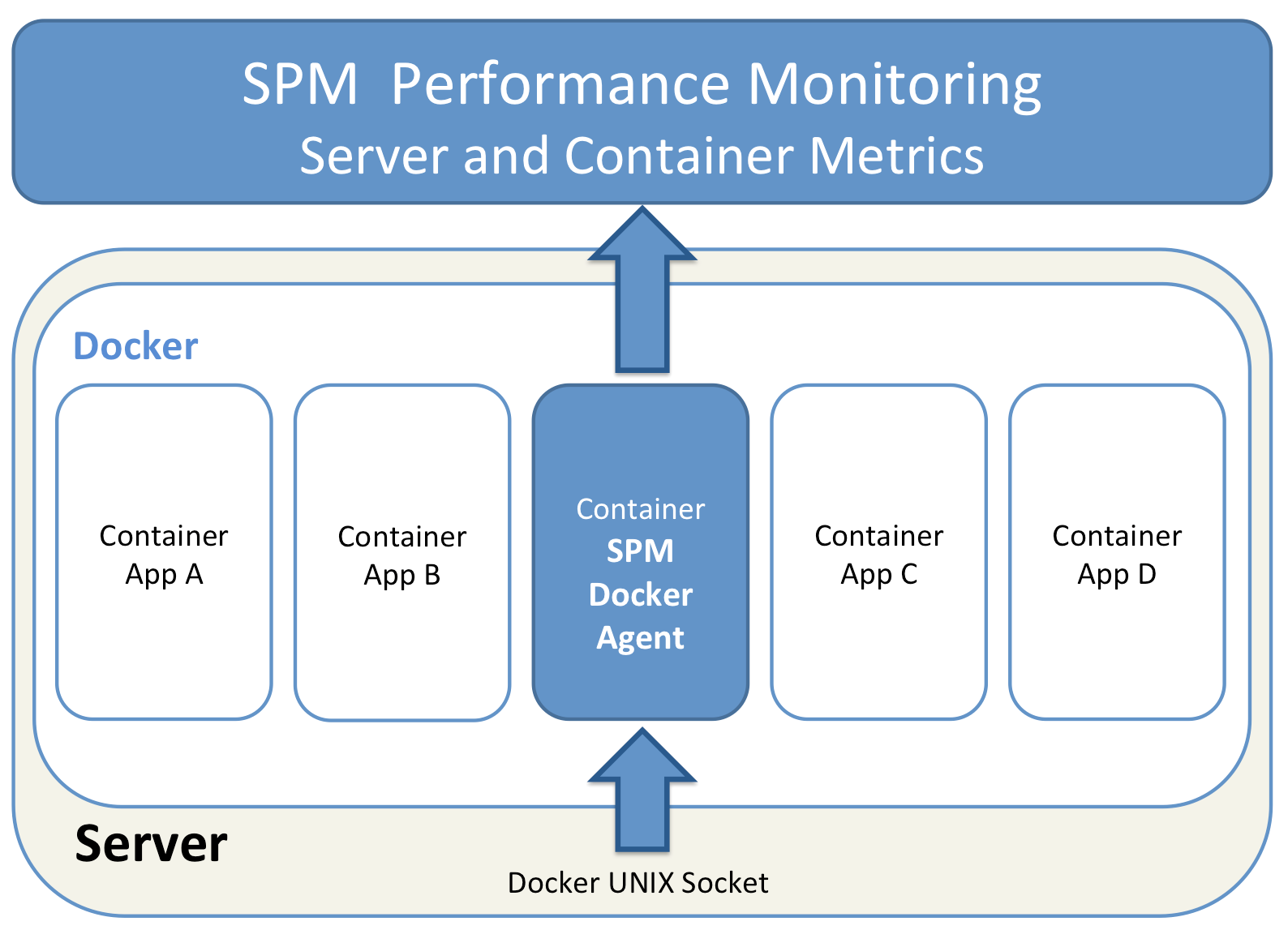
- If we deploy a single monitoring agent to the master node, it would miss host metrics for all other nodes because the Docker API doesn’t provide any host metrics. We could also not see how much memory, disk space or CPU the Docker Swarm node itself consumes. Solution: deploy the monitoring agents to each node for collecting the metrics locally.
- Assuming a larger cluster with a high volume of logs, events and metrics to collect, a single monitoring agent connected to the the master node would need to handle all operational data of the cluster. This would work for a small cluster but such an architecture would obviously be destined for failure on larger clusters. Guess what the solution is? It’s much better having an agent running on each node and distributing the monitoring and logging work over all nodes. If you do it right from the beginning, there is no need to change the deployment strategy later, when the cluster scales out.
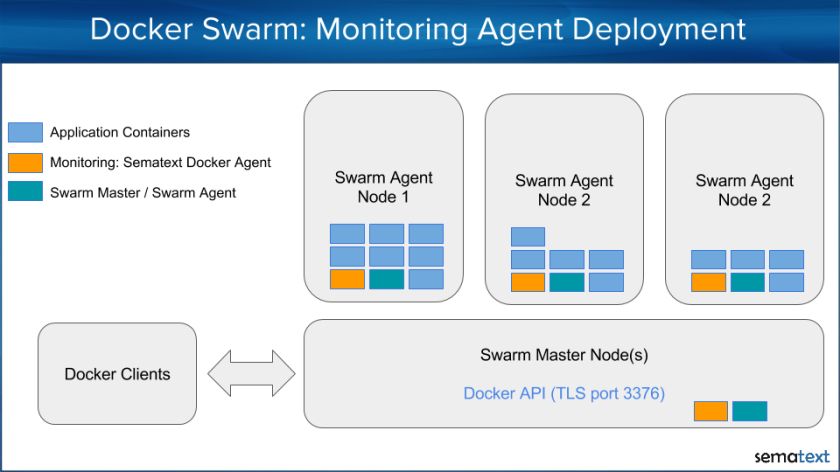
In the following example we assume that the master and agent nodes have the UNIX socket enabled in Docker daemon settings. This can be achieved by using –engine-env ‘DOCKER_OPTS=”-H unix:///var/run/docker.sock”‘ in the docker-machine create command. Use this Github Gist to create a Docker-Swarm Cluster with with enabled UNIX sockets. Later, we will see this helps simplify the deployment of any tool that needs to connect to the local Docker daemon – including monitoring and logging containers.
Let’s see how to deploy Sematext Agent to each node in a Docker Swarm Cluster with UNIX socket enabled in Docker-Daemon as just described.
When we started to work on Swarm Monitoring our first question was “Does Docker Swarm provide a deployment strategy for running exactly one instance of a service on each node?” We checked the documentation, but no dice. We found strategies like “spread, binpack, and random” (see https://docs.docker.com/swarm/scheduler/strategy/), but none of them would guarantee exactly one instance of a service on each node. The “spread” strategy spreads the containers evenly over all hosts. The “binpack” strategy fills up one node after another with containers, while “random” spreads containers randomly to nodes. There was seemingly no strategy suitable for monitoring services running only once on each node.
So how can we distribute the monitoring container to each host using Docker Swarm instead of bash script iterating over all nodes? It turns out it’s possible to define an affinity to ensure that containers that should run on the same host are scheduled together. In our case we use “anti-affinity” in the deployment strategy, which instructs Swarm not to deploy the container with Sematext Agent to hosts that already have that container running. In other words, it tells Docker Swarm to run no more than one Sematext Agent container on each Docker host. To do that we define a docker-compose.yml file with the “anti-affinity” specified in the container environment section:
sematext-agent: image: 'sematext/sematext-agent-docker:latest' environment: - LOGSENE_TOKEN=3b549a2c-653a-4832-xxx - SPM_TOKEN=fe31fc3a-4660-47c6-xxx - affinity:container!=sematext-agent* privileged: true restart: always volumes: - '/var/run/docker.sock:/var/run/docker.sock'
Finally, we use the docker-compose command to scale out the Sematext Docker Agent and deploy it to all Swarm cluster nodes. To do that we run:
eval $(docker-machine env swarm-master --swarm) docker-compose up -d # scale is == num nodes docker-compose scale sematext-agent=$(docker-machine ls | grep swarm | grep Running | wc -l)
After running the above commands, Sematext Docker Agent will be running on each node and within a minute you will receive Host and Container Metrics for all containers, all their Logs and all Docker events from all nodes in your Docker Swarm cluster. Complete visibility!
Please note there are many ways to create a Swarm cluster and you might have another setup, such as:
- TLS secured Docker daemon and no possibility to activate the unix socket: In this situation you have to deal with the existing Docker daemon setup, which typically uses TLS and authentication via certificates (for example, if you followed Docker’s instructions to create Swarm clusters using Docker-Machine). When the Docker socket is secured with TLS, each client – including Sematext Docker Agent – needs the certificates for authentication. This involves a bunch of parameters such as “DOCKER_HOST”, “DOCKER_CERT_PATH”, “DOCKER_TLS_VERIFY” and mounting of the certificate into the container. In addition we should know to which Docker daemon the agent should be connected (typically port 2375 for TCP, 2376 for TLS on each node and port 3376 on Swarm Master nodes for the Swarm API). We made this scenario easy with a deployment script for the Sematext Agent with TLS options provided by Docker-Machine.
- You use CoreOS to run Docker Swarm: In this case you could use fleet and systemd to distribute the agent to each node (simply install Sematext Agent with these instructions)
The deployment methods above should work for other monitoring tools or logging containers as well because most of such tools need to run on each node to collect the metrics locally.
If you have questions or special needs for monitoring more complex setups feel free to contact us. The Sematext Docker Agent is a turnkey-solution for Docker Logs, Metrics and Events – sign up here and give it a try (30-days free trial, no credit card needed).