Using Cloud (aka SaaS) applications is natural for most of us — simply sign up with your email, login and then use the service within minutes. The Cloud works particularly well with consumer-oriented services. Businesses, however, have slightly different needs.
Up until now, Sematext Apps offered only App sharing. For instance, if you had an SPM App for monitoring your Elasticsearch cluster, another SPM App for monitoring Spark, and a Logsene App where you shipped all your logs, you could invite one or more of your teammates to each one of those apps separately, and give them either Admin or User role. This works fine when you have just a few teammates or just a few Apps.
Larger organizations (aka Enterprises), however, have more complex needs due to their size and structure: they often have multiple departments and teams, many of whom have different roles and permissions.
With more and more large enterprises using Sematext Apps we recently introduced a new feature called “Account Sharing” to our SPM, Logsene and Site Search Analytics solutions.
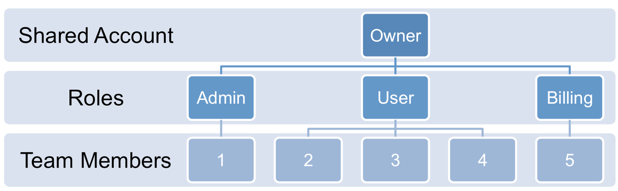
Example of Account Sharing with different Roles assigned to team members
As the diagram above shows, Account Sharing lets the Account Owner add more people to his Account and give them different roles – Admin, User, or Billing Admin. The benefit of Account Sharing over App Sharing is that by sharing your Account you can easily share all your Apps, Alerts, etc. with your teammates, without having to resort to all people using the same username/password for the shared account. Admins can invite additional people, Billing Admins have access to payment details, and Users can’t modify other people’s Alerts and other settings, though they can create, modify, and delete their own.
Once you have access to multiple Accounts you can easily switch between them, as shown here:

One can have access to an unlimited number of Accounts. Switching between them is seamless and does not require one to log out and log in. While App sharing is still possible (and we have no plans to remove it), Account Sharing makes teamwork much simpler!
See also:
- How can I share my apps with other users?
- What is the difference between OWNER, ADMIN, BILLING_ADMIN, and USER roles?
- When would I want to add someone as BILLING_ADMIN?
- What would be typical organization of roles for organization with many employees?
That’s all there is to it. If you’ve got questions about Account Sharing or feedback, please let us know!

