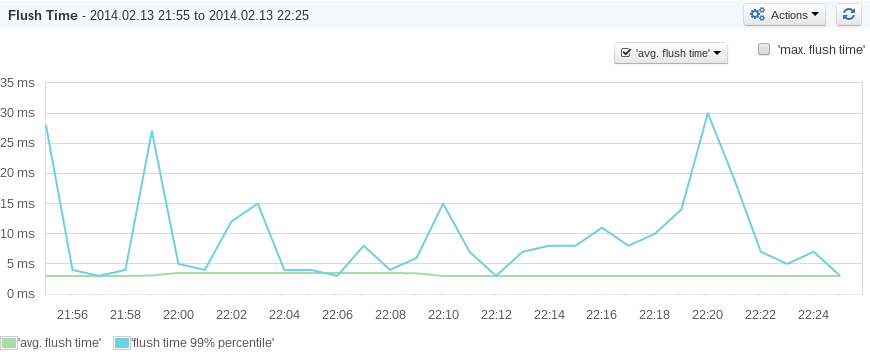
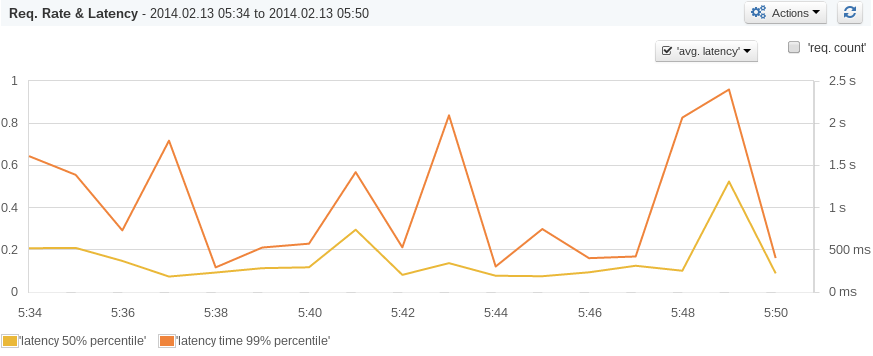
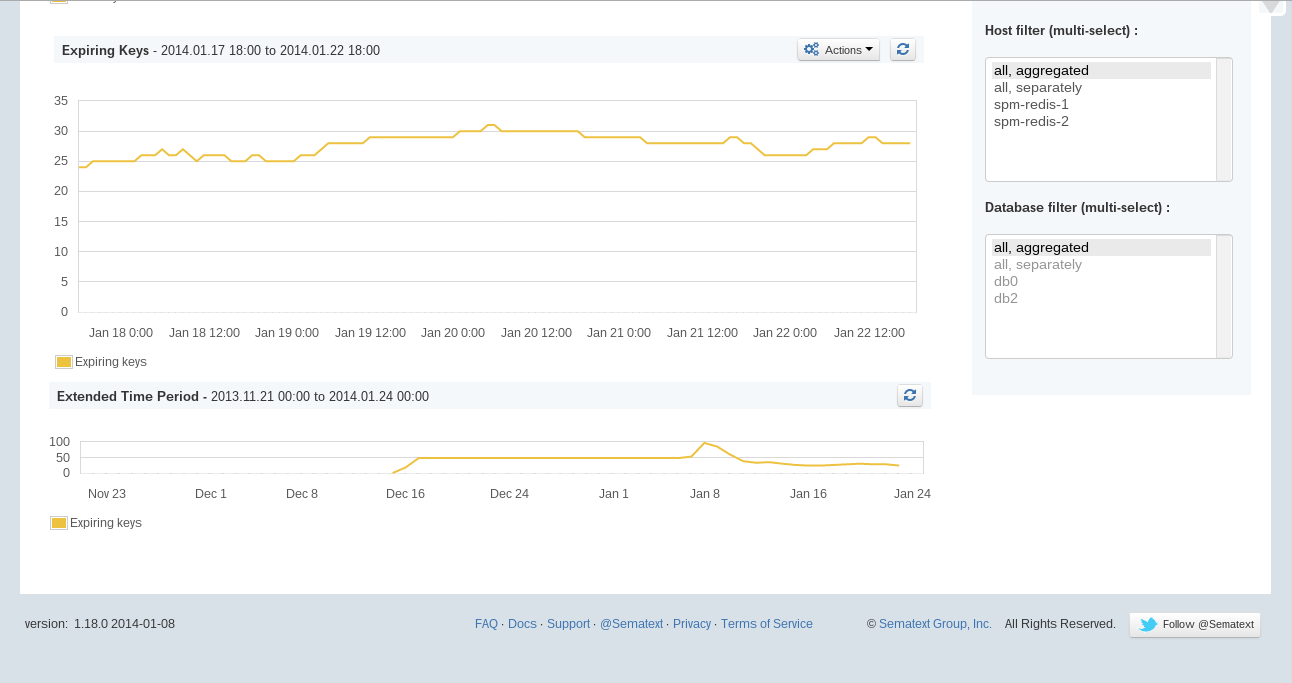
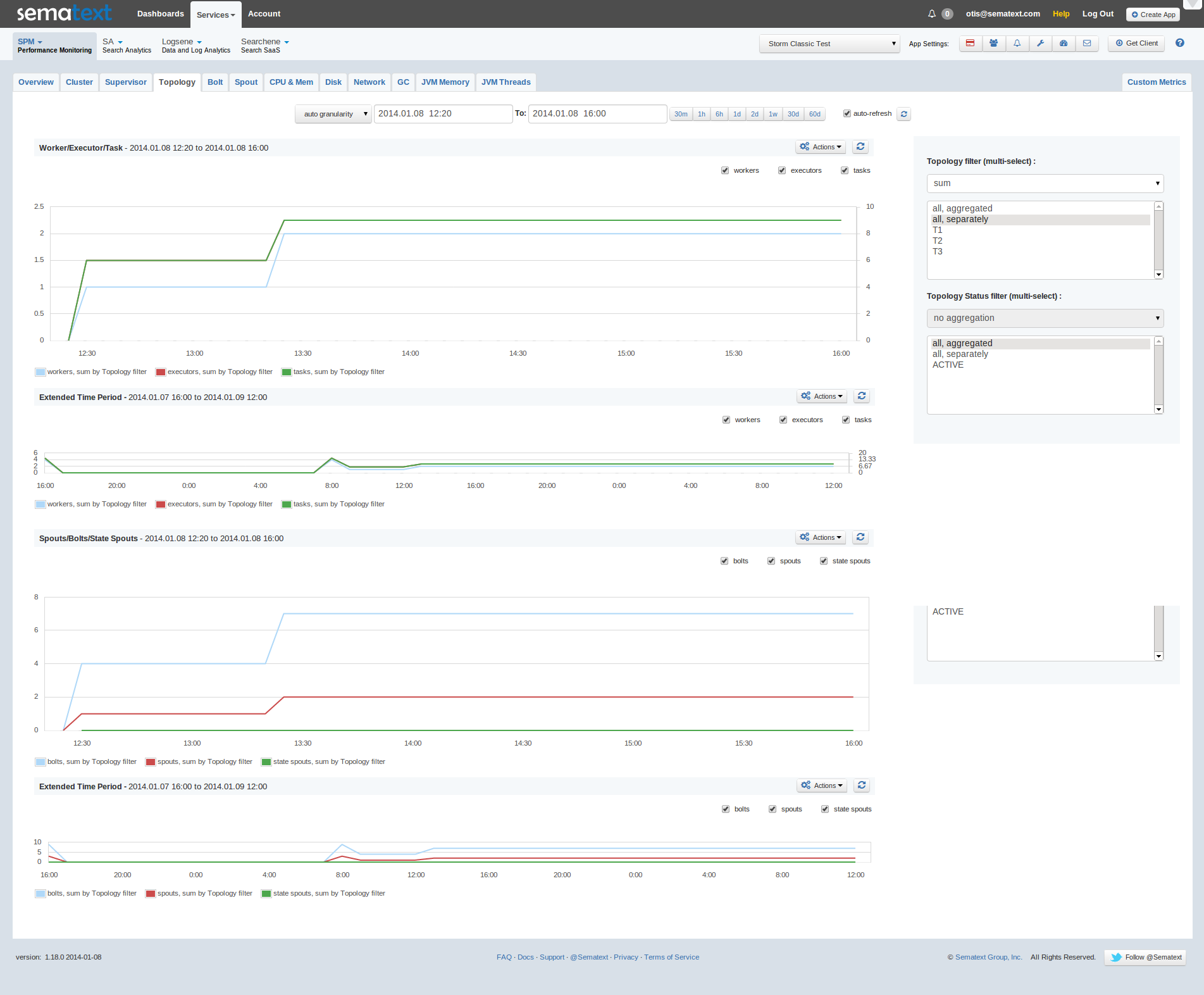
Use Elasticsearch now? Thinking about using Elasticsearch? Wish there was a comprehensive resource that pulled everything you ever wanted to know about Elasticsearch together in one place? Fret not — you are in luck!
All Elasticsearch, all the time
Sematext engineer Rafał Kuć has co-authored (with Marek Rogozinski) not one, but two(!) different Elasticsearch books: Elasticsearch Server and Mastering Elasticsearch. Considering that Elasticsearch has only been around a few years — not to mention how much is going on under the hood — it’s a pretty impressive accomplishment. Even more impressive? Rafal and Marek have just published a second edition of Elasticsearch Server that encompasses all the changes between Elasticsearch 0.20 and 1.0. So if you wish you knew more about Elasticsearch, look no further.
Here’s a brief Q&A with Rafal to add some insight:
Q: What has changed since the first edition of Elasticsearch Server?
A: After releasing the first edition of the book, which happened to be the first book about Elasticsearch, we got a nice amount of comments and suggestions which we took into consideration when writing the second edition. The first edition was based on Elasticsearch 0.20, so we already had a lot of material to work with when we were asked to write the second edition and take readers up to version 1.0. Some of the features we decided to write about were aggregations, new function queries allowing extensive score control, snapshotting, and others. Some features that are still used by Elasticsearch users, like faceting, did not need much updating. But others, like percolator, had to be completely rewritten.
Q: How much work was it?
A: We tried to make the book as good as we could so the readers could enjoy it and learn from it. And believe me, we both learned a lot during the writing of the first edition of the book and while writing Mastering Elasticsearch. We had a lot of comments both from the readers and from people working on the book’s Japanese translation. Thanks Jun!
We incorporated all the comments and suggestion, but it took time, of course. We also wanted to fully restructure the book so that it flowed better. Hopefully we achieved that. Of course, in addition to all that we had to rewrite major parts of the book to bring it up to date, review all the parts that we decided to leave in the book and make updates as needed, and then write the new sections.
Q: Where can someone buy it?
A: You can buy it from Amazon or direct from Packt Publishing.