Coming to you from the recent DevOps Days event in Warsaw and delivered by Sematext engineer Rafal Kuć, “Running High Performance and Fault Tolerant Elasticsearch Clusters on Docker” is chock full of practical information that will no doubt answer many of the questions you might have about this process.
Great news for for those of us who use PagerDuty and manage — or are considering managing — logs with Logsene: PagerDuty and Logsene are now integrated!
This integration is a huge time- and aggravation-saver for DevOps professionals who wouldn’t mind dramatically reducing the frequent “noise” from log-generated monitoring alarms.
In case you’re not familiar, Logsene is an enterprise-class log management solution. Logsene can receive logs from a wide array of logs shippers, such as Fluentd, Logstash, and Syslog, and supports many logging frameworks for programming languages such as: Java, Scala, Go, Node.js, Ruby, Python, .Net, Perl, and more. Among other capabilities, Logsene exposes the Elasticsearch API, works with Kibana and with Grafana (video), and has built-in alerts and anomaly detection. It is available both in the Cloud (SaaS) and On Premises.
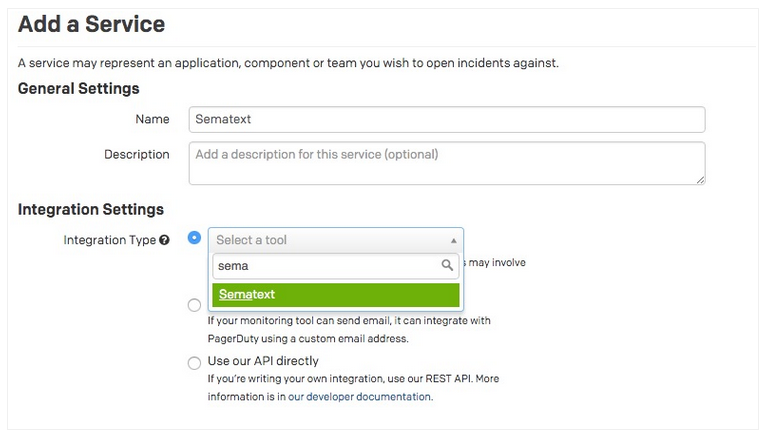
1) In your account, go to Services click +Add New Service
2) Enter in a name for your new service
3) Start typing “Sematext” for the Integration Type, which will narrow your filtering
4) Select an escalation policy. Then, adjust the incident settings to your liking, then click Add Service.
5) Once the service is created, you’ll be taken to the service page. On this page, you’ll see the Service Integration Key, which you will need when you configure Sematext products to send events to PagerDuty. Copy the Service Integration Key to the clipboard.
In Logsene
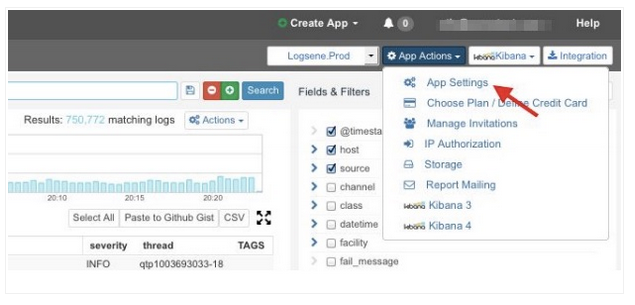
1) Navigate to App Actions of your Logsene App by clicking the App Settings menu item.
2) Navigate to Alerts / PagerDuty
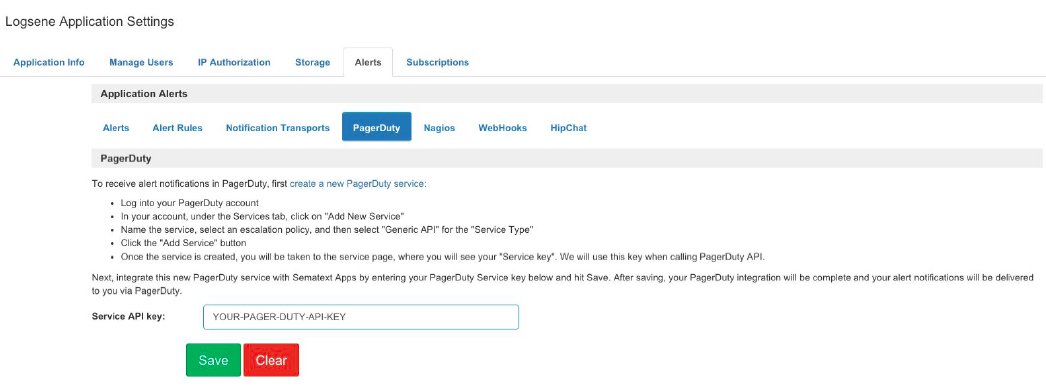
3) Enter the API key from PagerDuty in the field Service API key.
4) Press Save
5) To enable PagerDuty Notifications, navigate to Alerts /Notification Transports
6) Select PagerDuty
Done. Every alert from your Logsene app will be forwarded to PagerDuty, where you can manage escalation policies and configure notifications to other services like HipChat, Slack, Zapier, Flowdock, and more.
New Year, New Feature in SPM! We are happy to announce the immediate availability of NetMaps in SPM! Check out why they are useful or watch the short video below.
Ever wondered how different components of distributed apps are actually connected over the network? When it comes to troubleshooting of distributed application stacks like Apache Kafka, Spark, Hadoop, Cassandra, Solr, or Elasticsearch — not to mention Microservice architectures or Docker Containers — information about the deployed infrastructure becomes critical. That architecture diagram you drew N months ago? It’s probably out of date. Apps we run today are often very dynamic. Instances, nodes, and containers come and go, whether because of elastic up/down scaling or other reasons.
Discovering This Dynamic Infrastructure
Watching the actual network traffic on all nodes could quickly answer many questions for DevOps engineers doing troubleshooting or planning setup changes. For example:
Which nodes are online and active?
How nodes are connected to other nodes?
What are the dependencies between network services?
What is the consumed bandwidth between nodes?
Which applications run on a specific network node?
Visualize Network Connections
Designed to visualize network connections and answer the above questions instantly, NetMaps also include:
Automatic Discovery of network nodes and applications
Filtering by application and host name
Automatic Visualizations as Network Map and Chord Diagrams
Interactive Explorer for following network links for each application node
Bandwidth consumption for all incoming and outgoing network connections
Navigation from the NetMap to all nodes and related performance metrics of the monitored App
The best practice is to activate network monitoring on all application server nodes, which communicate with databases, message brokers, search engines etc. in that way it is easy to see how client applications communicate with backend servers.
NetMap “Map” View
NetMap “Chord” View
It is very easy to activate Network Monitoring in SPM Client, a collector for Host and Application Metrics. Intelligent network filters ensure that the resource usage for the network monitoring stays low while capturing all relevant packets to explore your infrastructure using the “NetMap” Tab in SPM. If you find network maps interesting, you might also be interested in SPM’s AppMap feature for JVM applications to discover relationships between monitored JVM applications such as Elasticsearch, Solr, Cassandra, Spark or Kafka, …
We hope you like this new addition to SPM. Got ideas how we could make it more useful for you? Let us know via comments, email or @sematext.
Not using SPM yet? Check out the free 30-day SPM trial by registering here. There’s no commitment and no credit card required.
If you’ve found your way to this post then chances are high that you’re having second thoughts about diving into a New Relic APM subscription. You’re not alone. In fact, we hear from many fellow DevOps engineers looking at performance monitoring solutions who check out New Relic APM — or who are already using it — because it is so widely known, but wonder if there is a better tool, specifically with traits like:
Better pricing
On Premises deployment (not just SaaS)
Integration of metrics, logs and events in a single UI
So why not give SPM a try? You can check out a free 30-day trial by registering here. There’s no commitment and no credit card required. Even better — combine SPM with Logsene to make the integration of performance metrics, logs, events and anomalies more robust for those looking for a single pane of glass.
For many of us in the DevOps field, MongoDB is a critical part of our IT stack. With today’s acquisition of WiredTiger, MongoDB is further establishing itself as the NoSQL DB built to support massive data processing and storage. It would be an understatement to say that MongoDB does a lot, with many organizations using it as their backend storage framework, analytics backend, and so on.
So your MongoDB cluster really, really needs to be in tip-top shape. All the time. And if it’s not then you need to know asap — or better yet — prevent problems before they kick in and make your life difficult. That’s where SPM comes in — with MongoDB monitoring, alerting and anomaly detection. MongoDB exposes a boatload of metrics, but instead of just throwing all of them on endless charts, we’ve taken the time to cherry pick what we think are the top 50 most valuable MongoDB metrics to monitor. We have furthermore made it possible to filter the MongoDB metrics by server, as well as a database and table where possible.
The key metric groups we track are:
Database Operations
Database Memory
Database Storage
Documents
Locks
Network
Database Journal
Background Flushes
The Overview chart below provides 9 charts with MongoDB key metrics:
Row 3 adds Collection/Document Metrics, Locks, and wait times; followed by Network Metrics for MongoDB
SPM for MongoDB Overview
In case you monitor a MongoDB cluster, the Server Tab provides a quick overview for the Health of each node:
SPM Server View
The Reports on the left side of the screen below provide detailed information for each group of metrics. Let’s have a quick look at them.
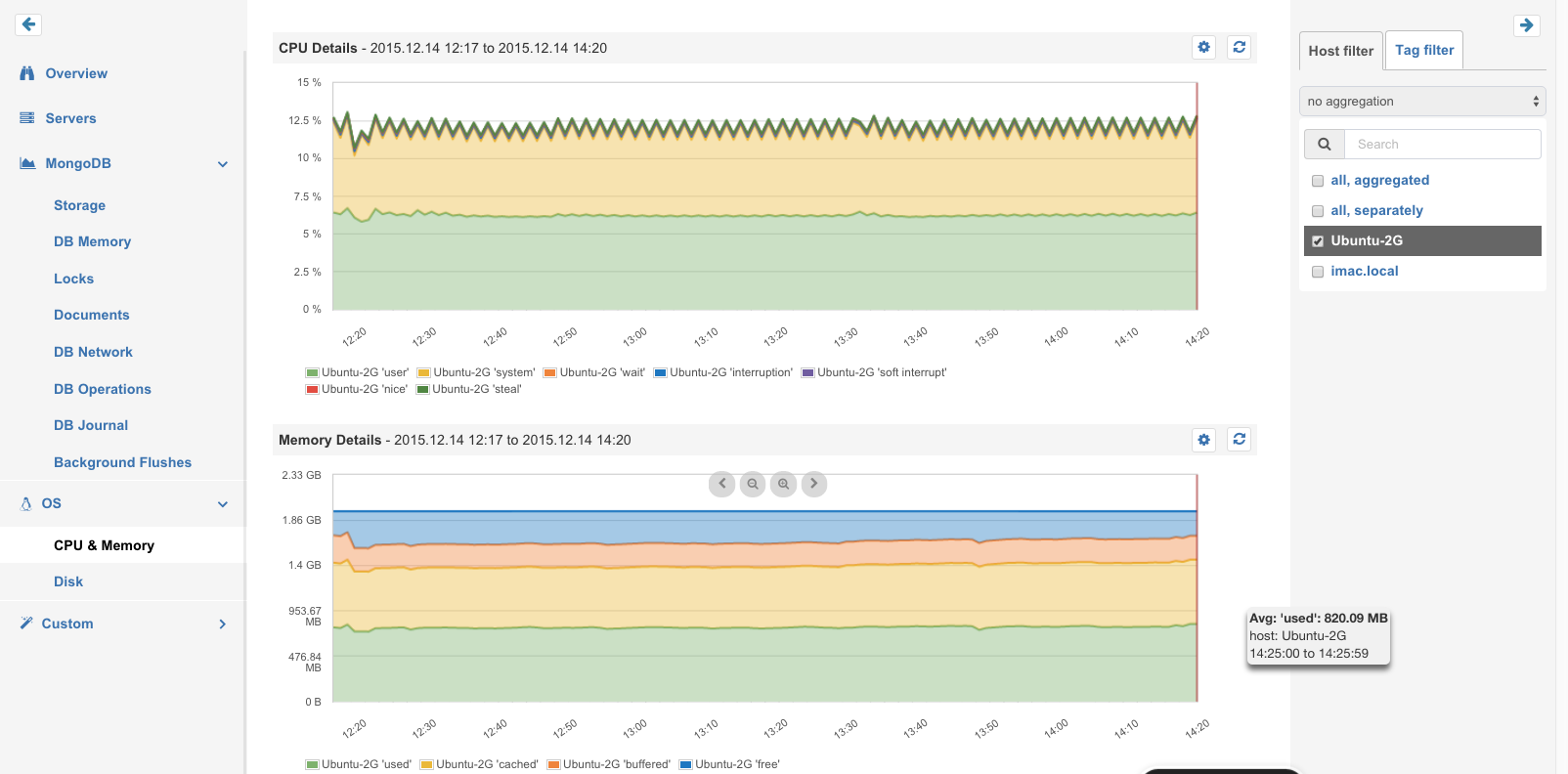
OS Metrics: CPU Metrics, Memory Usage, Disk Space and I/O
Below is an example of some of the key MongoDB Metrics found in SPM:
Database Operations: Counters for Queries, Insert, Update, Delete and other commands for the main database plus replica operations
Database Memory: Resident-, Virtual-, Mapped-, and Journal Memory
Database Storage: Size of Data Files, Namespace Files, DB Files etc., plus Size of Objects, Number of Collections and Objects
MongoDB Storage & Collections
The screenshot below shows:
Documents: Counters for Documents inserted, updated or returned by queries
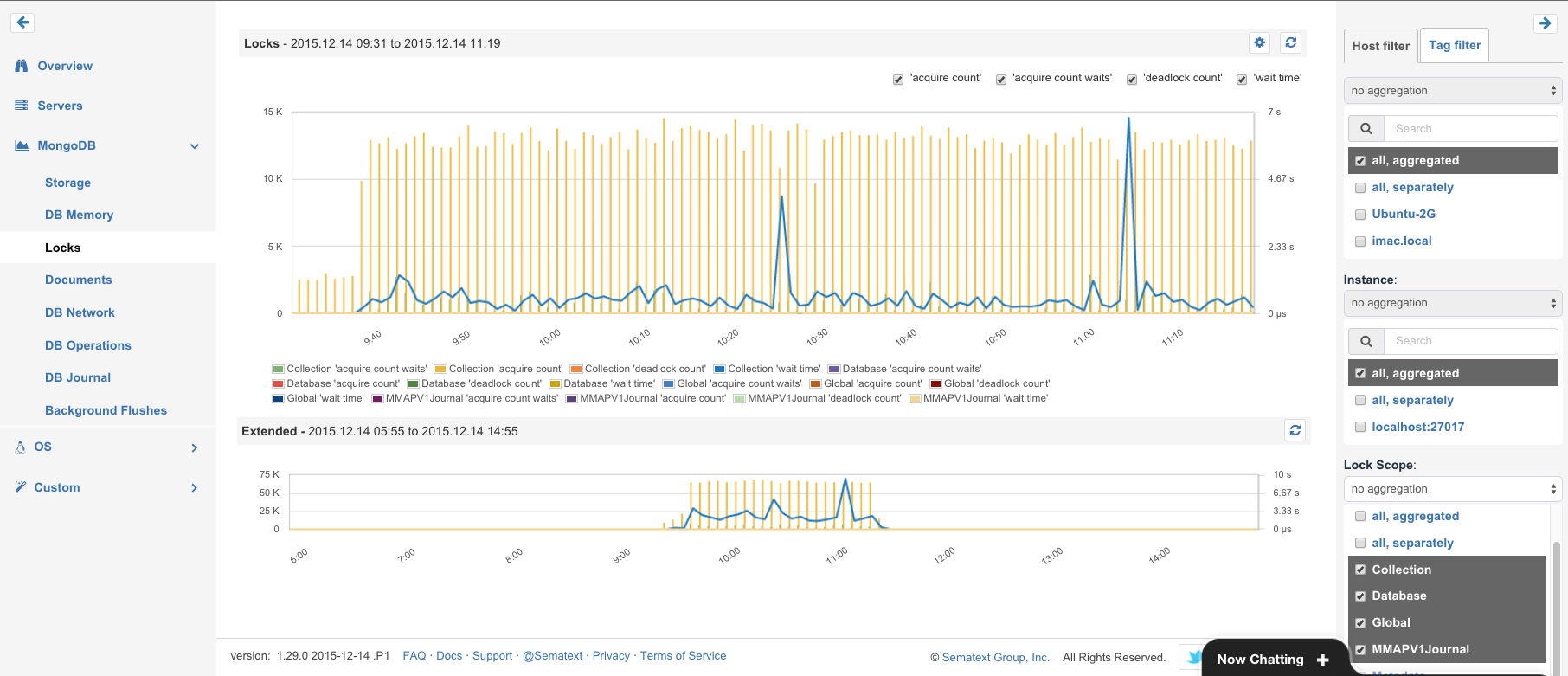
Locks: Lock counters and lock acquisition wait times for Global, Database, Collection and Journal level. Since MongoDB 3.x Locks are not always global. SPM shows a breakdown for all lock types. These metrics are good candidates for alerting, when anomalies are detected. Simply add an alert from the menu in the top-left corner in each chart.
Metrics for all MongoDB Locks
Other key MongoDB metrics that SPM displays are:
Network: Number of client connections, Received and transmitted data, Request rate
Database Journal: Commits, Early Commits, Commit times and lock times
MongoDB Journal Metrics
In case you like to see MongoDB metrics together with the Top Node.js Metrics, you might like the idea of putting MongoDB and Node.js metrics from SPM for Node.js in a custom dashboard:
SPM Custom Dashboard with MongoDB Locks and Node.js Event Loop Latency
We hope you like this new addition to SPM. Got ideas how we could make it more useful for you? Let us know via comments, email or @sematext.
Not using SPM yet? Check out the free 30-day trial by registering here. There’s no commitment and no credit card required. Even better — combine SPM with Logsene to make the integration of performance metrics, logs, events and anomalies more robust for those looking for a single pane of glass.
Sematext has just been recognized by Docker as an Ecosystem Technology Partner (ETP) for logging. This designation indicates that Logsene has contributed to the logging driver and is available to users and organizations that seek solutions to capture logging data for monitoring their Dockerized distributed applications.
Log Management for Docker
“Sematext brings years of logging and monitoring expertise to the Docker community,” said Nick Stinemates, Head of Business Development and Technical Alliances at Docker. “As an active participant in the Docker community, Sematext has provided logging solutions like Logsene and SPM for Docker, and contributed valuable user education and resources through informative webinars and blogs.”
Logsene & Docker
Logsene is a centralized logging, alerting and anomaly detection solution, available in the Cloud and On Premises. Logsene delivers critical operational and business insights from data generated by Docker containers, applications and servers, and other devices. Some DevOps engineers even think of Logsene as “ELK Stack on steroids.” Logsene also integrates seamlessly with SPM, a performance monitoring, alerting and anomaly detection tool for Docker and many other platforms used by DevOps teams.
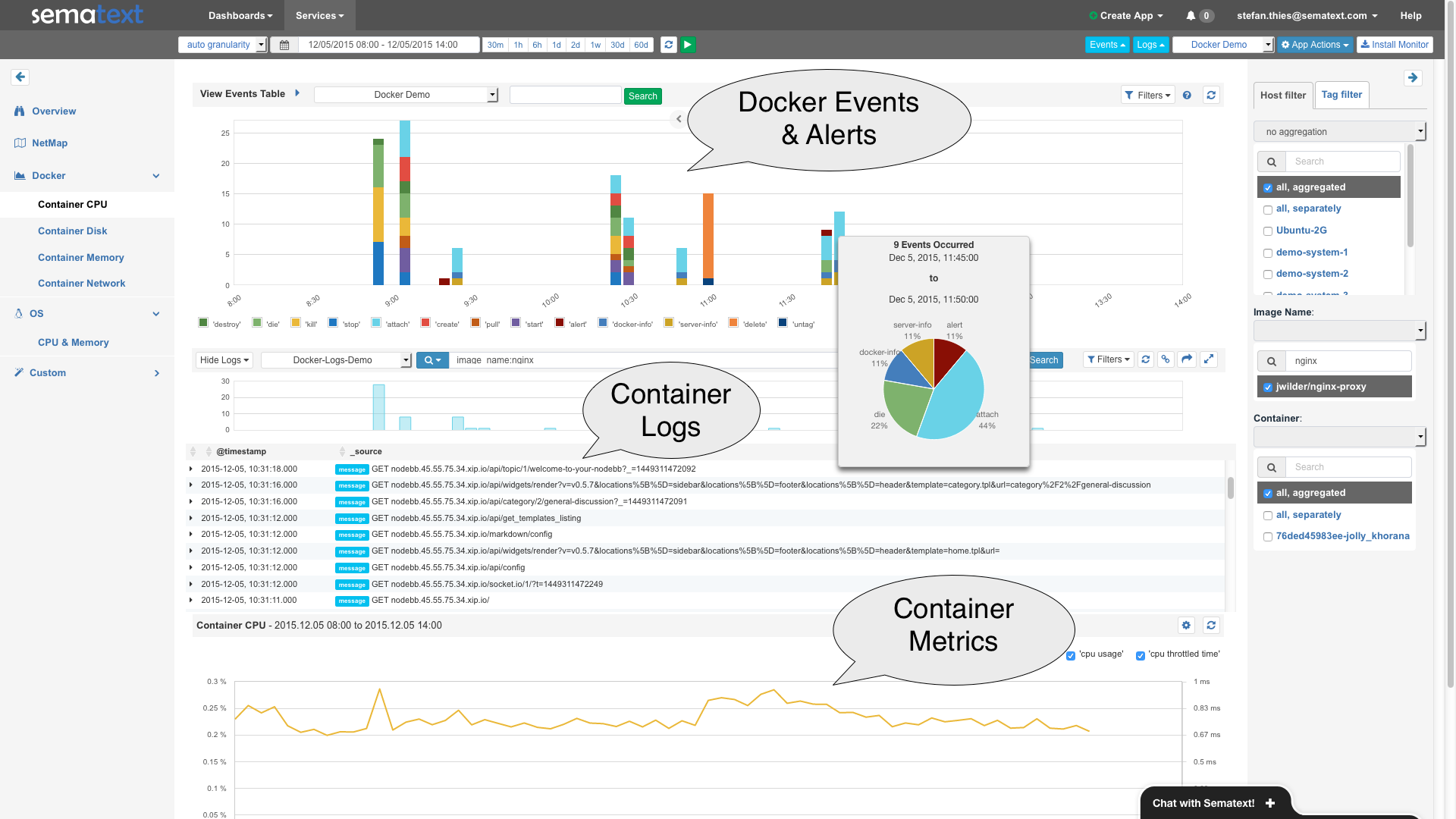
The following screenshot shows expanded views for Docker Events and Alerts (top), Container Logs (middle) and Container Metrics (bottom):
Sematext SPM, showing Docker Events, Logs and Metrics
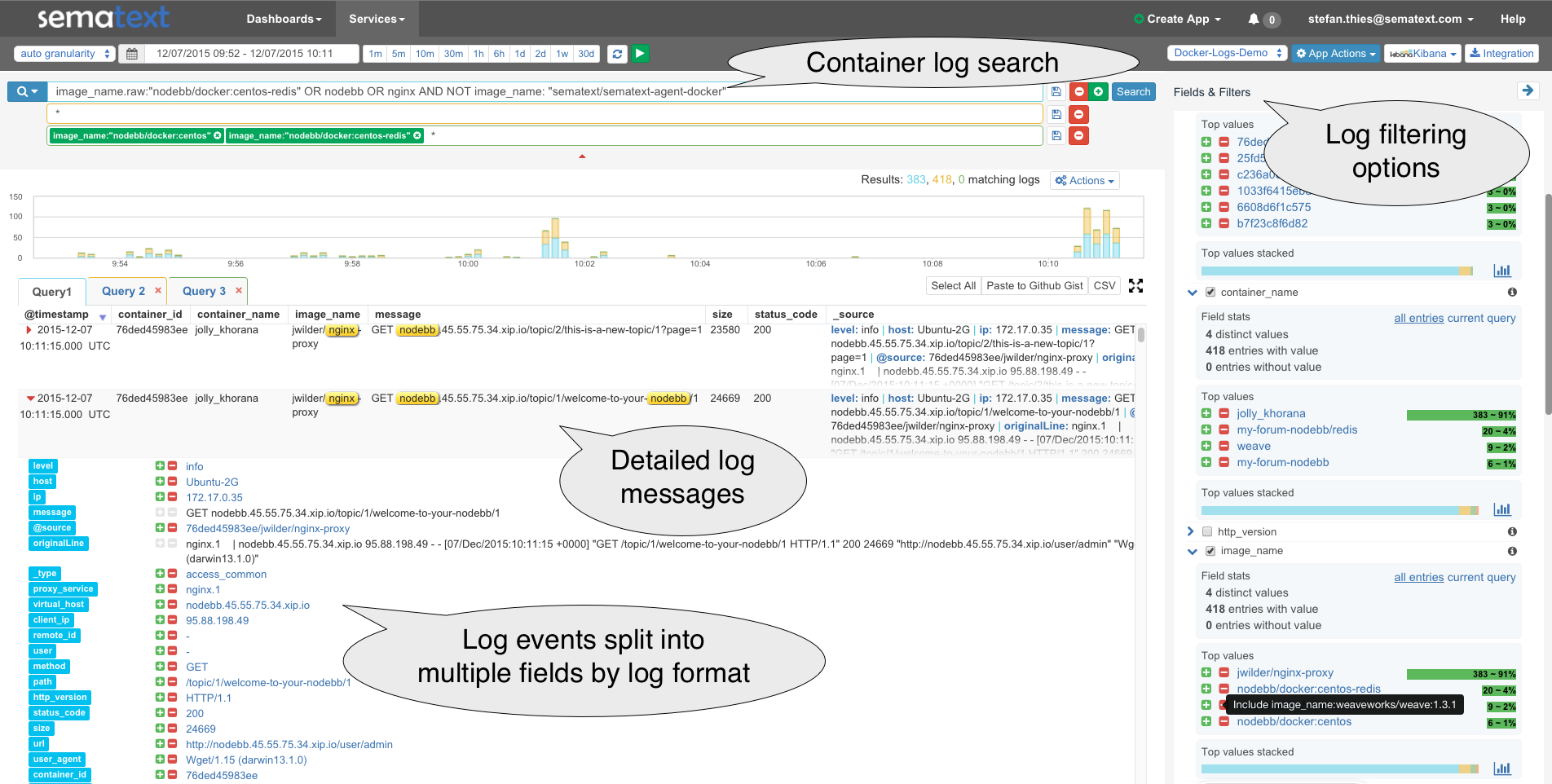
If you need more functionality to slice and dice logs then move to the Logsene UI shown below. The screenshot shows Container Log search (top) and detailed log messages tagged with container information and parsed fields (middle). Both the detail view in the middle and the Fields & Filters on the right side contain buttons to drill down into logs – e.g., to filter for the logs of a specific Docker Image or Docker Container.
Logsene User Interface – showing Docker log search, filtering options, log messages, & log events sorted by format
1-Minute Deployment in Tutum
One of the benefits of using SPM and Logsene for Docker monitoring, logging, and events is how easily they can be launched on Tutum. It’s basically one minute: click-click-done! For Docker users this means a single solution, a single container that captures not just logs or just metrics, but both container metrics and logs, plus Docker events, plus Docker host metrics and its logs.
Sematext Docker Agent on Docker Hub
Sematext Docker Agent image is available on Docker Hub, and we shared the Tutum Stackfile for Sematext Docker Agent on Stackfiles.io – but the easiest way is to go via Sematext UI, which generates the stackfiles for you, including Application Tokens, as demonstrated in the video.
Sematext Docker Agent Stackfile in Tutum Cloud, ready to deploy
Docker’s ETP Program
Docker’s ETP program recognizes ecosystem partners like Sematext that have demonstrated integration with the Docker platform. As part of the program, Docker will highlight a capability area within the application lifecycle, validate integration and communicate the availability of the partner’s solution to the community and the market. The goal of the program is to ensure that logging tools like Logsene have been working with Docker to ensure the highest degree of availability and performance of distributed applications. Like the other partners in this program, Sematext has proven integration with the Docker platform and has demonstrated that Logsene is able to record logging data for dockerized applications.
“Sematext has been on the forefront of Docker monitoring, along with Docker event collection, charting and correlation with metrics,” said Otis Gospodnetić, Sematext’s Founder and CEO. “So it was a natural next step to incorporate Docker logging via our Logsene log management solution. The combination of SPM and Logsene not only allows for correlation of Docker metrics and logs, but also metrics and logs of applications running inside containers, along with anomaly detection and alerting. All this makes it much easier to troubleshoot performance and other issues much faster and with a lot less hassle than using more traditional or siloed solutions.”
Not using Logsene yet? Check out the free 30-day trial by registering here (ping us if you’re a startup, a non-profit, or educational institution – we’ve got special pricing for you!). There’s no commitment and no credit card required.
Sematext has combined the power of SPM and Logsene in a single pane of glass – a unified view into all the key bits of operational intelligence every DevOps engineer needs: server and application performance metrics, logs, events, anomalies, alerts, ChatOps integrations, etc. In other words, the whole is greater than the sum of its parts.
Metrics + Logs Correlation using SPM and Logsene Together in One UI
This video demonstrates how the SPM + Logsene combination solves the problems of having too much data to manage yourself and the disconnect when metrics and logs are siloed. We address two of the most common problems — and their solutions — below the video.
Problem 1 – Big Data, Big Burden: Servers, Containers, Apps, and Devices spew out more and more data: more metrics, more logs, more events. Collecting and storing all this data is a challenge and is often not cheap both in terms of time invested in building large-scale data collection, storage, and retrieval systems, maintaining them, as well as providing the adequate infrastructure to run them.
Solution: Focus on your organization’s core business, your core strength, and outsource needlessly painful or expensive parts to those who specialize in them. We already outsource all the time, except we don’t call it “outsourcing”: we buy food, we don’t grow or raise it. We buy cars and don’t build them. Most of us don’t buy physical servers any more. Why? Because others do that better, faster, cheaper.
Problem 2 – Metrics vs. Log Silos: Collecting and visualizing performance metrics and getting alerts when things go awry is great, but performance charts can tell us only so much. Code instrumentation, like SPM’s Transaction Tracing, goes deeper and provides more insight, but still doesn’t tell us the whole story. Similarly, collecting logs and being able to search them is very valuable. Unfortunately, oftentimes APM and log management solutions live in separate silos that don’t really talk to each other.
Solution: Don’t waste your time jumping between multiple disconnected solutions, be they open-source or commercial. Time is the most precious thing each of us has, and our time as DevOps engineers is very expensive. Use a tool or service that gives you access to as many bits of operational information that you need as possible. Not only is this more efficient, and thus cheaper, it’s also much more pleasant than jumping between solutions for browser and terminal, top, vmstat, dstat, less, grep, etc. which are needlessly manual and get boring.
Troubleshooting Doesn’t Need To Take Over Your Life
Troubleshooting production performance issues, dealing with APM alerts and even looking at logs (don’t even think about grepping!) isn’t that hard or time consuming. Well, as long as you have the right tools, that is.
Cloud & On Premises Deployments
Unlike most monitoring and logging solutions, Sematext offers both Cloud and On Premises deployments for SPM and Logsene. We’re happy to discuss package pricing if you’d like to combine both products.
Got ideas how we could make metrics and logs correlation more useful for you? Let us know via comments, email or @sematext.
Not using SPM and/or Logsene yet? Check out the free 30-day trial by registering here (ping us if you’re a startup, a non-profit, or educational institution – we’ve got special pricing for you!). There’s no commitment and no credit card required.
Fresh from DevOps Days in Warsaw and delivered by Sematext engineer Rafal Kuć, “Running High Performance and Fault Tolerant Elasticsearch Clusters on Docker” is chock full of practical information that will no doubt answer many of the questions you might have about this process.
We’ve been hard at work on our centralized logging SaaS / On-Premises solution – Logsene – and we’re confident the logging fans among us will enjoy the new Live Tail functionality.
Live Tail Benefits
Logsene Live Tail has several important benefits, including:
shows logs in real-time as they arrive into your Logsene app
lets you filter logs to only see those you’re most interested in (e.g., eliminate info logs which are high-volume, noisy and don’t contain critical information)
useful for deploying new software versions; see new errors right away and quickly go in and fix them
Video
Logsene Live Tail is best seen, not told. Check out this short video for a detailed look!
We hope you like this new addition to Logsene. Got ideas how we could make it more useful for you? Let us know via comments, email or @sematext.
Not using Logsene yet? Check out the free 30-day trial by registering here (ping us if you’re a startup, a non-profit, or educational institution – we’ve got special pricing for you!). There’s no commitment and no credit card required. Even better — combine Logsene with SPM to make the integration of performance metrics, logs, events and anomalies more robust for those looking for a single pane of glass.
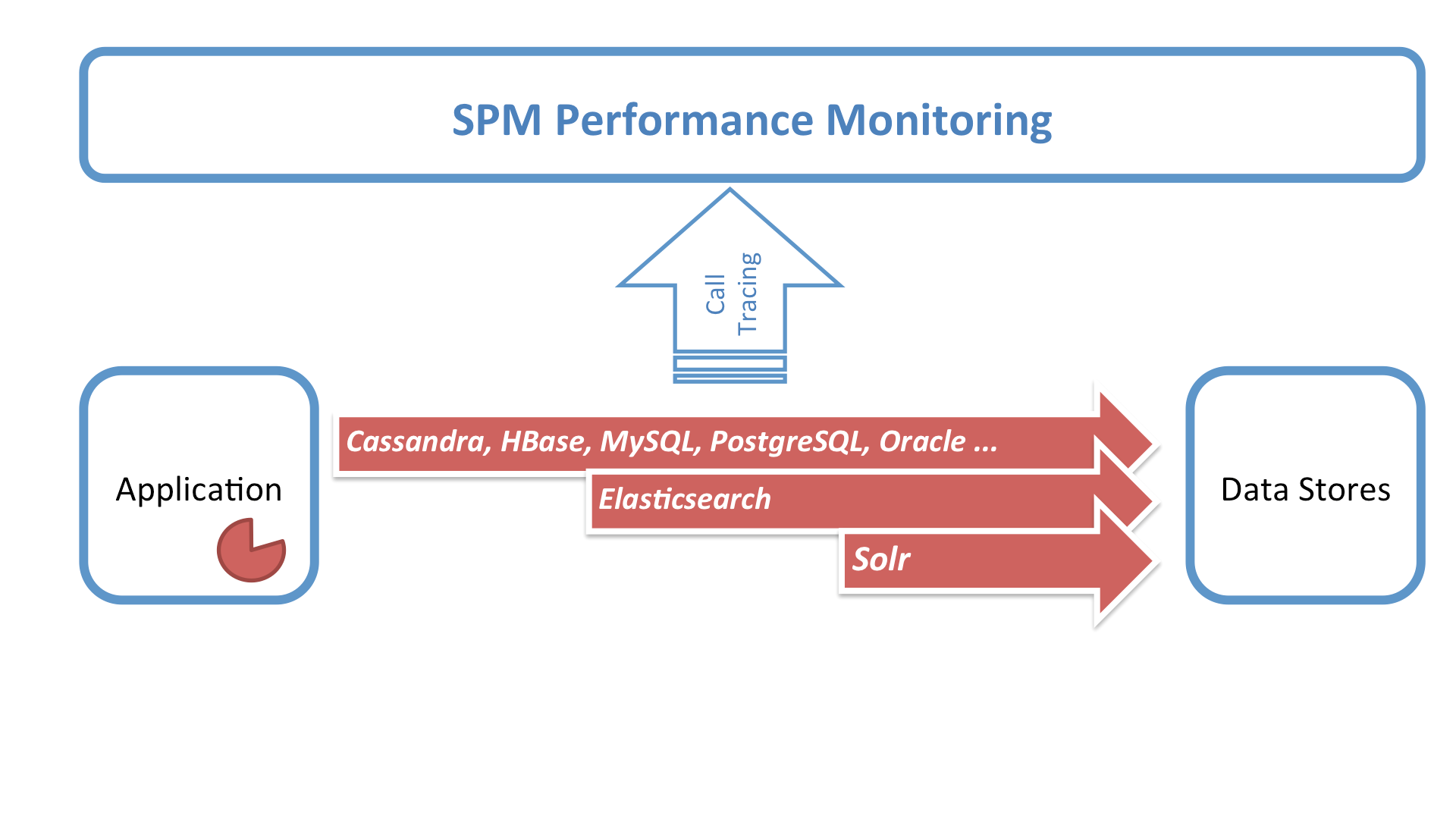
If you run Elasticsearch, Solr, or any backend you communicate with using SQL (via JDBC), like SparkSQL, Apache Cassandra (CQL), Apache Impala, Apache Drill, MySQL, PostgreSQL, etc., you’ll like what we’ve just added to SPM. We call it Database Operations and in SPM you can find it in the new Database report:
If you didn’t watch the video, here’s what Database Operations gives you:
Top 5 operation types across all your data stores or filtered to a specific data store type
Top 5 operation types by speed, throughput, or simply their volume
Time-series reports for volume, throughput, and latency broken down by operation type
Ability to view all collected operations, not just the slowest ones, filter by database type or by operation type, sorted by average or total duration, or throughput
Sparklines that show last 5 minute values and trends
Top 10 slowest individual operations and drill-in details
Integration with Transaction Tracing, so you can correlate slow data store operations with the actual transaction/request that triggered slow operations
Important:
To get this information add SPM agent to the application that is talking to a data store (e.g. Solr or Elasticsearch or MySQL or …). This is because the SPM agent captures operations at that client layer, not in the server itself.
Don’t forget – when you enable Database Operations you will also automatically get Transaction Tracing, as well as the cool AppMaps – enjoy! 🙂
Got ideas how we could make Database Operations better and more useful to you? Let us know via comments, email or @sematext.
Grab a free 30-day SPM trial by registering here (ping us if you’re a startup, a non-profit, or educational institution – we’ve got special pricing for you!). There’s no commitment and no credit card required.