There are a lot of sources of logs these days. Some may come from mobile devices, some from your Linux servers used to host data, while other can be related to your Docker containers. They are all supported by Logsene. What’s more, you can also ship logs from your Microsoft Windows based hosts and visualize them using Logsene. In this blog post we’ll show how to send your Windows Event Logs to Logsene in a way that will let you build great visualizations and really see what is happening on your Windows-based systems.
Continue reading “Sending your Windows Event Logs to Logsene using NxLog and Logstash”
Author: Rafał Kuć
Sematext engineer, books author, trainer, speaker.
Using Filebeat to Send Elasticsearch Logs to Logsene
One of the nice things about our log management and analytics solution Logsene is that you can talk to it using various log shippers. You can use Logstash, or you can use syslog protocol capable tools like rsyslog, or you can just push your logs using the Elasticsearch API just like you would to send data to a local Elasticsearch cluster. And like any good DevOps team, we like to play with all the tools ourselves. So we thought the timing was right to make Logsene work as a final destination for data sent using Filebeat.
With that in mind, let’s see how to use Filebeat to send log files to Logsene. In this post we’ll ship Elasticsearch logs, but Filebeat can tail and ship logs from any log file, of course.
Continue reading “Using Filebeat to Send Elasticsearch Logs to Logsene”
SolrCloud: Dealing with Large Tenants and Routing
Many Solr users need to handle multi-tenant data. There are different techniques that deal with this situation: some good, some not-so-good. Using routing to handle such data is one of the solutions, and it allows one to efficiently divide the clients and put them into dedicated shards while still using all the goodness of SolrCloud. In this blog post I will show you how to deal with some of the problems that come up with this solution: the different number of documents in shards and the uneven load.
Imagine that your Solr instance indexes your clients’ data. It’s a good bet that not every client has the same amount of data, as there are smaller and larger clients. Because of this it is not easy to find the perfect solution that will work for everyone. However, I can tell one you thing: it is usually best to avoid per/tenant collection creation. Having hundreds or thousands of collections inside a single SolrCloud cluster will most likely cause maintenance headaches and can stress the SolrCloud and ZooKeeper nodes that work together. Let’s assume that we would rather go to the other side of the fence and use a single large collection with many shards for all the data we have.
No Routing At All
The simplest solution that we can go for is no routing at all. In such cases the data that we index will likely end up in all the shards, so the indexing load will be evenly spread across the cluster:

However, when having a large number of shards the queries end up hitting all the shards:
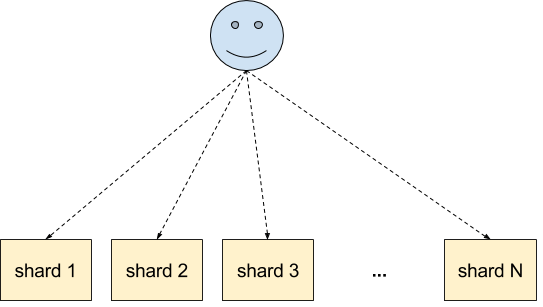
This may be problematic, especially when dealing with a large number of queries and a large number of shards together. In such cases Solr will have to aggregate results from the large number of shards, which can take time and be performance expensive. In these situations routing may be the best solution, so let’s see what that brings us. Continue reading “SolrCloud: Dealing with Large Tenants and Routing”
Solr 5: Replication Throttling
With the release of Solr 5.0, the most recent major version of this great search server, we didn’t only get improvements and changes from the Lucene library. Of course, we did get features like:
- segments control sum
- segments identifiers
- Lucene using only classes from Java NIO.2 package to access files
- lowered heap usage because of new Lucene50Codec
…but those features came from the Lucene core itself. Solr introduced:
- improved usability for start-up scripts
- scripts for Linux service installation and running
- distributed IDF calculation
- ability to register new handlers using the API (with jar uploads)
- replication throttling
- …and so on
All of these features come with the first release of branch 5 of Solr, and we can expect even more from future releases — like cross data center replication! We want to start sharing what we know about those features and, today, we start with replication throttling.
Custom Elasticsearch Index Templates in Logsene
One of the great things about Logsene, our log management tool, is that you don’t need to care about the back-end – you know, where you store your logs. You just pick a log shipper (here are Top 5 Log Shippers), point it to Logsene (here’s How to Send Logs to Logsene) and you are done. Logsene takes care of everything for you – your logs stop filling up your disk, you don’t have to worry about log compression and rotation, your logs get indexed so when you need to troubleshoot issues you have one place where you get see and search all your logs from all your applications, servers, and environments. This is all nice and dandy, but what if your logs are special and you want them analyzed in a specific way, and not the way Logsene’s predefined index templates and analysis work? To handle such use cases we’ve recently made it possible for Logsene users to define how their logs are analyzed. Let’s look at an example.
Continue reading “Custom Elasticsearch Index Templates in Logsene”
Berlin Buzzwords 2014 – Side by Side with Elasticsearch and Solr
Last year at Berlin Buzzwords two Sematext Engineers had the opportunity to give two talks. Radu talked about “JSON Logging with Elasticsearch” (video, slides) and Rafał did the second round of Solr vs Elasticsearch in his talk “Battle of the Giants, round 2” (video, slides). We were also happy to be sponsoring Berlin Buzzwords 2013. This year, we decided to go for a talk where two of us can talk on the same stage, at the same time. On Tuesday, 27th of May, at 11:30, in the Frannz Club Radu and Rafał will be giving a talk called “Side by side with Solr and Elasticsearch“.

Solr – established, mature and well known open-source search server, commonly used. Elasticsearch – still young, but quickly gaining popularity, with over 200k downloads per month. Both search servers are based on Lucene – the open-source full text searching Java library, but each with their own extensions, their pros and cons.
We all know that Solr and Elasticsearch are different, but what those differences are and which solution is the best fit for a particular use case is a frequent question. We will try to make those differences clear, not by showing slides and comparing them, but by showing on online demo of both Elasticsearch and Solr:
- Set up and start both search servers. See what you need to prepare and launch Solr and Elasticsearch.
- Index data right after the server was started using the “schemaless” mode
- Create index structure and modify it using the provided API
- Explore different query use cases
- Scale by adding and removing nodes from the cluster, creating indices and managing shards. See how that affects data indexing and querying.
- Monitor and administer clusters. See what metrics can be seen out of the box, how to get them and what tools can provide you with the graphical view of all the goodies that each search server can provide.
If you want to come, hear about both Solr and Elasticsearch from @sematext and how to achieve similar things, what how they behave and don’t see too many slides, come join us 🙂
Parameterizing Queries in Solr and Elasticsearch
We all know how good it is to have abstraction layers in software we create. We tend to abstract implementation from the method contracts using interfaces, we use n-tier architectures so that we can abstract and divide different system layers from each other. This is very good – when we change one piece, we don’t need to touch the other parts that only knew about method contracts, API’s, etc. Why not do the same with search queries? Can we even do that in Elasticsearch and Solr? We can and I’ll show you how to do that.
Continue reading “Parameterizing Queries in Solr and Elasticsearch”
Video: Scaling Solr with SolrCloud
During last year’s Lucene Revolution conference in Dublin we had the opportunity to give four talks, one of which was Scaling Solr with SolrCloud. Through it we wanted to share our experiences around scaling Solr, especially as we have experience in running Solr internally and as a team of search consultants. Enjoy the video and/or the slides!
Note: we are looking for engineers passionate about search to join our professional services team. We’re hiring planet-wide!
Video: Administering and Monitoring SolrCloud Clusters
As you know, at Sematext, we are not only about consulting services, but also about administration, monitoring, and data analysis. Because of that, during last year’s Lucene Revolution conference in Dublin we gave a talk about administration and monitoring of SolrCloud clusters. During the talk, Rafał Kuć discusses some administration procedures for SolrCloud like collection management and schema modifications with the schema API. In addition, he also talks about why monitoring is important and what to pay attention to. Finally, he shows three real life examples of monitoring usefulnesses. Enjoy the video and/or the slides!
Note: we are looking for engineers passionate about search to join our professional services team. We’re hiring planet-wide!
Berlin Buzzwords 2013 – Two Talks from Sematext
Last year at Berlin Buzzwords we were proud to give three talks. Alex talked about “Real-time Analytics with HBase” (slides, video), Otis talked about large scale monitoring in his talked titled “Large Scale ElasticSearch, Solr & HBase Performance Monitoring” (slides, video) and Rafał gave a talk about how we scale ElasticSearch clusters in his “Scaling Massive ElasticSearch Clusters” talk (slides, video). We were also very happy to be one of the sponsors of this great conference 🙂 Because we really enjoyed the conference we decided to submit a few proposals this year and they got accepted. In this years schedule we will be giving the following talks:
Radu: JSON Logging with ElasticSearch
This talk is about aggregating loooots of logs – searching of seriously big data. We’ll go through everything we can possibly go through in 20 minutes. We’ll look at how, where, when, why, and what to log. We’ll show how to use Elasticsearch as a data store for logs and what the benefits of doing so are. We’ll discuss advantages and disadvantages of logging in JSON, which is easily processed by machines, over traditional logging, which is easily processed by humans. Finally, we’ll explore how you can get your logs – JSON or not – into Elasticsearch, run searches and statistics on them, and create pretty graphs you can’t stop staring at.
Rafał: Battle of the Giants, Round 2

Learn about how both of these great enterprise search servers are evolving and adding new features. We will be comparing the latest and greatest versions of Solr and ES, both of which are using Lucene 4.x and bringing different approaches to handling codecs, per field similarities, and more. Of course, we’ll not only look at technical aspects of both Apache Solr and ElasticSearch, but will also dig into the makeup of their contributors, compare the code and of course the user community. By the end of the talk you’ll learn the main differences when it comes to these two search servers, how they handle shard and replica distribution, automatic data replication, and different query types. In addition, you’ll learn what the admin APIs for both Solr and ElasticSearch look like and how to use them to control and alter your cluster state. Last, but not least, you’ll learn what to avoid when using ElasticSearch or Apache Solr.
[Note: for those of you who don’t have the time or inclination to go through all the technical details, here’s a high-level, up-to-date (2015) Solr vs. Elasticsearch overview]
We hope to see some of you in Berlin. If these topics are of interest to you, but you won’t be coming to Berlin, feel free to get in touch, leave comments, or ping @sematext. As usual we’ll be posting slides after the talks and the organizers will probably record the talk and publish it after the conference. And if you love working with things our talks are about, we are hiring world-wide!

