Another year is behind us, and it’s been another good year for us at Sematext. Here are the highlights in the chronological order. If you prefer looking non-chronological overview, look further below.
January
We started the year by doing a ton of publishing on the blog – about Solr-Redis, about SPM and Slack, about Solr vs. Elasticsearch – always a popular topic, Spark, Kafka, Cassandra, Solr, etc. Logsene being ELK as a Service means we made sure users have the freedom and flexibility to create custom Elasticsearch Index Templates in Logsene.
February
We added Account Sharing to all our products, thus making it easier to share SPM, Logsene, and Site Search Analytics apps by teams. We made a big contribution to Kafka 0.8.2 by reworking pretty much all Kafka metrics and making them much more useful and consumable by Kafka monitoring agents. We also added support for HAProxy monitoring to SPM.
March
We announced Node.js / io.js monitoring. This was a release of our first Node.js-based monitoring monitoring agent – spm-agent-nodejs, and our first open-source agent. The development of this agent resulted in creation of spm-agent – an extensible framework for Node.js-based monitoring agents. HBase is one of those systems with tons of metrics and with metrics that change a lot from release to release, so we updated our HBase monitoring support for HBase 0.98.
April
The SPM REST API was announced in April, and a couple of weeks later the spm-metrics-js npm module for sending custom metrics from Node.js apps to SPM was released on Github.
May
A number of us from several different countries gathered in Krakow in May. The excuse was to give a talk about Tuning Elasticsearch Indexing Pipeline for Logs at GeeCon and give away our eBook – Log Management & Analytics – A Quick Guide to Logging Basics while sponsoring GeeCon, but in reality it was really more about Żubrówka and Vișinată, it turned out. Sematext grew a little in May with 3 engineers from 3 countries joining us in a span of a couple of weeks. We were only dozen people before that, so this was decent growth for us.
Right after Krakow some of us went to Berlin to give another talk: Solr and Elasticsearch – Side by Side with Elasticsearch and Solr: Performance and Scalability. While in Berlin we held our first public Elasticsearch training and, following that, quickly hopped over to Hamburg to give a talk at a local search meetup.
June
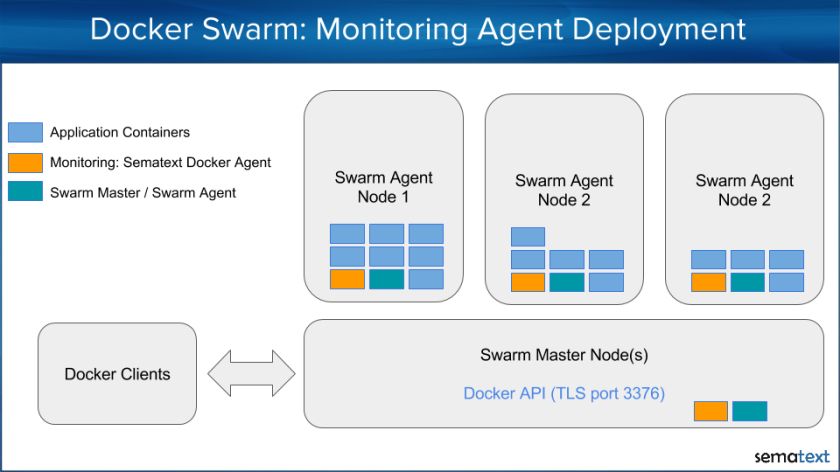
In June we gave a talk on the other side of the Atlantic – in NYC – Beyond POC: Processing Metrics, Logs and Traces … at Scale. We were conference sponsors there as well and took part in the panel about microservices. We published our second eBook – Elasticsearch Monitoring Essentials eBook. The two most important June happenings were the announcement of Docker monitoring – SPM for Docker – our solution for monitoring Docker containers, as well as complete, seamless integration of Kibana 4 into Logsene. We’ve added Servers View to SPM and Logsene got much needed Alerting and Anomaly Detection, as well as Saved Searches and Scheduled Reporting.
July
In July we announced public Solr and Elasticsearch trainings, both in New York City, scheduled for October. We built and open-sourced Logsene Command Line Interface – logsene-cli – and we added Tomcat monitoring integration to SPM.
August
At Sematext we use Akka, among other things, and in August we introduced Akka monitoring integration for SPM and open-sourced the Kamon backend for SPM. We also worked on and announced Transaction Tracing that lets you easily find slow transactions and bottlenecks that caused their slowness, along with AppMaps, which are a wonderful way to visualize all your infrastructure along applications running on it and see, in real-time, which apps and servers are communicating, how much, how often there are errors in each app, and so on.
September
In September we held our first 2 webinars on Docker Monitoring and Docker Logging. You can watch them both in Sematext’s YouTube channel.
October
We presented From zero to production hero: Log Analysis with Elasticsearch at O’Reilly’s Velocity conference in New York and then Large Scale Log Analytics with Solr at Lucene/Solr Revolution in Austin. After Texas we came back to New York for our Solr and Elasticsearch trainings.
November
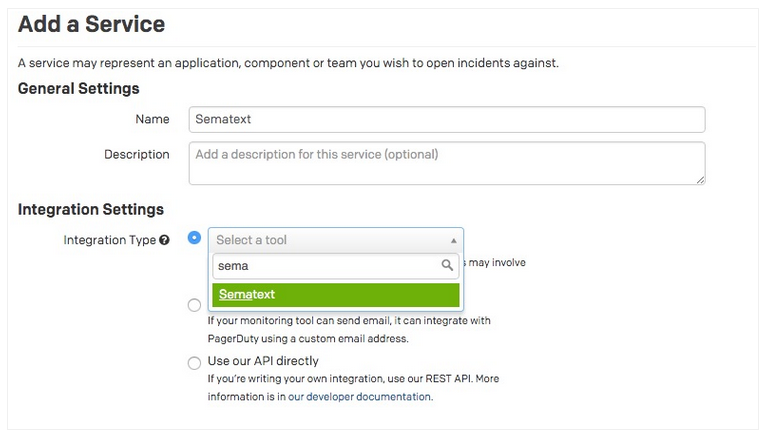
Logsene users got Live Tail in November, while SPM users welcomed the new Top Database Operations report. Live Tail comes in very handy when you want to semi-passively watch out for errors (or other types of logs) without having to constantly search for them. While most SPM users have SPM monitoring agents on their various backend components, Top Database Operations gives them the ability to gain more insight in performance between the front-end/web applications and backend servers like Solr, Elasticsearch, or other databases by putting the monitoring agents on applications that act as clients for those backend services. We worked with O’Reilly and produced a 3-hour Working with Elasticsearch Training Video.
December
We finished off 2015 by adding MongoDB monitoring to SPM, joining Docker’s ETP Program for Logging, further integrating monitoring and logging, ensuring Logsene works with Grafana, writing about monitoring Solr on Docker, publishing the popular Top 10 Node.js Metrics to Watch, as well as a SPM vs. New Relic APM comparison.
Pivoting the above and grouping it by our products and services:
Logsene:
- Live Tail
- Alerting
- Anomaly Detection
- logsene-cli + logsene.js + logagent-js
- Saved Searches
- Scheduled Email Reporting
- Integrated Kibana
- Compatibility with Grafana
- Search AutoComplete
- Powerful click-and-filter
- Native charting of numerical fields
- Account Sharing
- REST API
SPM:
- Transaction Tracing
- SPM Tracing API
- AppMap
- NetMap
- On Demand Profiling
- Integration with Logsene
- Expanded monitoring for Elasticsearch, Solr, HBase, and Kafka
- Added monitoring for Docker, Node.js, Akka, MongoDB, HAProxy, and Tomcat
- Birds Eye Servers View
- Account Sharing
- REST API
Webinars:
- Docker Monitoring
- Docker Logging
Trainings:
- Elasticsearch training in Berlin
- Solr and Elasticsearch trainings in New York
eBooks:
- Elasticsearch Monitoring Essentials
- Log Management & Analytics – A Quick Guide to Logging Basics
Talks / Presentations / Conferences:
- Lucene/Solr Revolution, Austin, TX – Large Scale Log Analytics with Solr
- Velocity Conference, NYC, NY – Log Analysis with Elasticsearch
- Berlin Buzzwords, Berlin, Germany – Side by Side with Elasticsearch and Solr: Performance and Scalability
- GeeCon, Krakow, Poland – Tuning Elasticsearch Indexing Pipeline for Logs
- DevOps Days, Warsaw, Poland – Running High Performance and Fault Tolerant Elasticsearch Clusters on Docker
- DevOps Expo, NYC, NY – Process Metrics, Logs, and Traces at Scale
Trends:
All numbers are up – our SPM and Logsene signups are up, product revenue is up a few hundred percent from last year, we’ve nearly doubled our blogging volume, our site traffic is up,we’ve made several UI-level facelifts for both apps.sematext.com and www.sematext.com, our team has grown, we’ve increased the number of our Solr and Elasticsearch Production Support customers, and we’ve added Solr and Elasticsearch Training to the list of our professional services.