… with Syslog, LogStash, Elasticsearch, Kibana, and friends, one might add. If you liked Recipe: rsyslog + Elasticsearch + Kibana, you’ll like this presentation. We’ve also published the actual 25-minute video of the presentation.
For the occasion, Sematext is giving a 20% discount for all SPM applications. The discount code is MONEU2013.
Also, Manning is giving a 44% discount for Elasticsearch in Action and all the other books from their website. The discount code is mlmoneu13cf.
For those interested in Logsene, our Logstash + Syslog + Elasticsearch + Kibana service mentioned in the talk, we’ll notify you when Logsene becomes fully (and freely!) available next month if you leave your name on the Logsene page.
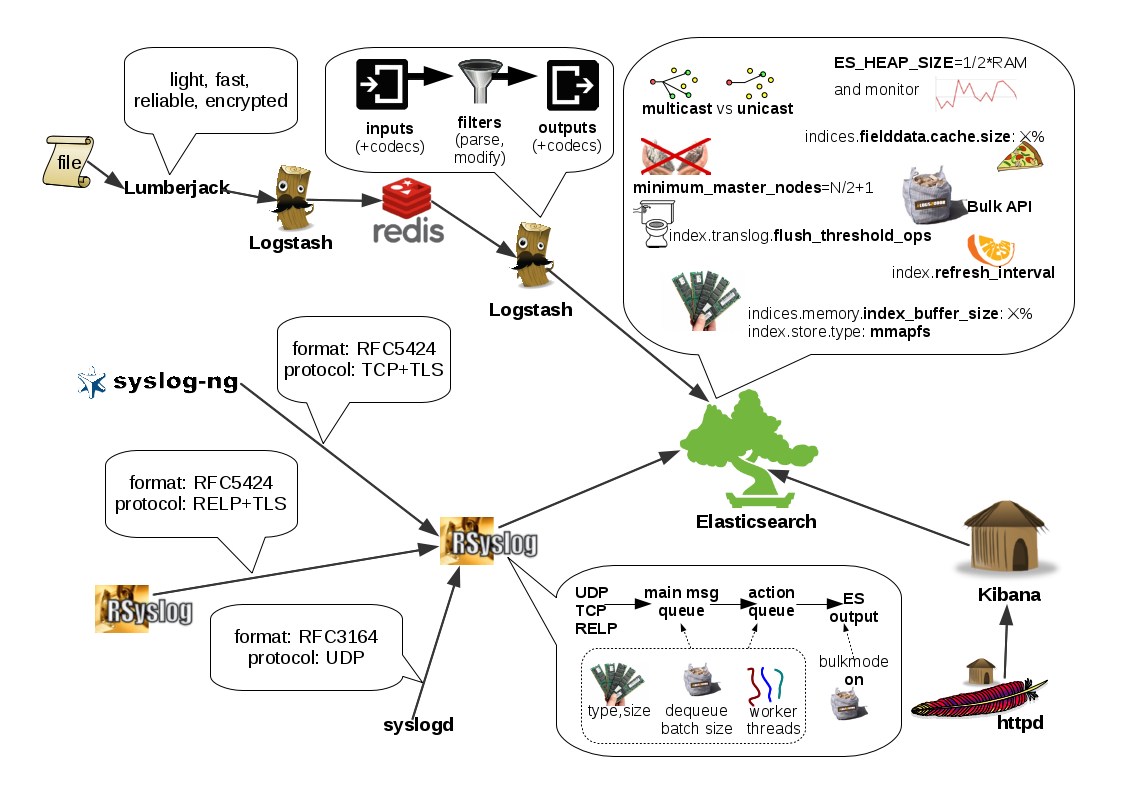
Below is a sketchnote of the whole talk, which was printed and given to all attendees. Click on the image to get the full resolution.

Hi,
I’m very interested in your experience and architecture choices.
Is it possible to you to answer this questions ?
– why did you used Lumberjack and not directly Logstash client ?
Logstash 1.2.1 can push directly to ElasticSearch 0.90.5,
– why did you used Redis ?
– in this case, what is the desired function used by Redis ?
ElasticSearch 0.90.5 has a Redis river.
For more I know it’s possible to add a filters and codecs into Logstash but it’s the same thing too onto ElasticSearch
– What is the interest to use a second Logstash between Redis and Elasticsearch ?
Thank in avance for your returns 😉
Hi Stephane,
The architecture involving Logstash was just an example, it’s not something I’m currently using in production. That said, here are the the reasons for providing this example in the first place 🙂
– Lumberjack is a lot lighter on your server (e.g.: waaay lower memory consumption) than a Logstash agent. If that isn’t a problem for you, I’d go with a simpler architecture of using Logstash directly. Less moving pieces == less trouble 🙂
– Redis in this case is used as a buffer. For example, if the ES cluster can’t keep up with a spike of load, or needs to be restarted.
– I didn’t know about the Redis river. Although I still don’t know about the 0.90.5 one. I see one for 0.90.1:
https://github.com/sksamuel/elasticsearch-river-redis
and one for 0.20.x:
https://github.com/leeadkins/elasticsearch-redis-river
Anyway, I’m guessing rivers should work as well, if you do all the processing you need with the Logstash that’s placed before Redis. I think using Logstash after Redis instead of a river would still make sense if:
a) you’re using the elasticsearch_http output, which gives you the flexibility of having a different ES version than the one Logstash is built against
b) you want to do most of the processing (such as grok) after Redis. This makes sense if you make the Logstash before Redis to do little/no processing, so that it doesn’t become a bottleneck. If you do the heavy processing after Redis and Logstash proves to be too slow, data gets buffered in Redis, giving you a chance to fire up another Logstash instance and fix the problem. If the same slowness happens with the Logstash before Redis, you might lose data.
I hope I’ve answered your questions. Otherwise, please let me know 🙂